Localizador de Duplicatas
Outras línguas: English Español Français Deutsch 日本語 한국어 Русский 中文
O localizador de duplicatas é uma aplicação de código aberto para detectar texto similar em um ou mais arquivos. Pode ser usado para encontrar duplicatas 100% assim como conteúdo que é semelhante, mas não idêntico. A ferramenta é compatível com vários formatos, incluindo texto simples, Markdown e XML.
A ferramenta de localização de duplicatas pode ajudar você com:
- Detecção de plágio
- Gerenciamento de conteúdo
- Otimização de SEO
- Desduplicação de dados
Exemplo de conteúdo duplicado
Aqui está um exemplo rápido para te dar uma ideia do que a ferramenta detecta:
Como usar
- Baixe o aplicativo. Alternativamente, você pode construir você mesmo a partir de as fontes.
- Certifique-se de que o Java 16 ou uma versão posterior esteja instalado no seu computador
- No terminal, abra a pasta com o arquivo .jar que você baixou
-
Execute
java -jar duplicate-finder.jarcom os seguintes parâmetros:Parâmetro Significado Exemplo -r/--rootobrigatórioCaminho relativo ou absoluto para a pasta onde você deseja procurar conteúdo duplicado -r=./my-project/-o/--outputCaminho relativo ou absoluto para a pasta onde você deseja salvar os resultados da análise. Se nenhum diretório for especificado, o localizador de duplicados usará o diretório de trabalho atual. -o=./my-project/duplicates/-f/--fileMaskLista separada por vírgula de extensões de arquivo para analisar. Por padrão, todos os arquivos são analisados. -f=md,mdx-p/--parserO que considerar como um pedaço de texto. As seguintes opções estão disponíveis:
- md – um elemento markdown
- line – uma única linha de texto
- xml – um elemento XML
- adoc – elemento AsciiDoc
- file – o conteúdo do arquivo inteiro
- auto – tentativa de inferir da máscara de arquivo
-i=md-l/--minLengthO comprimento mínimo (em caracteres) para um fragmento de texto a ser analisado. Padrão: 100 (fragmentos de texto com menos de 100 caracteres são ignorados) -l=150-s/--minSimilarityO grau mínimo de semelhança entre dois fragmentos de texto para serem considerados duplicados. Padrão: 0.9 (90%) -s=0.85-d/--minDuplicatesO número mínimo de duplicados para que um grupo de duplicados seja relatado. Padrão: 1 (um duplicado é suficiente) -d=5-ui/--uiSe deve usar a interface interativa ou não. Opções: - none – sem interface, apenas grava em arquivos
- swing – interface antiga
- compose – nova interface, padrão
-ui=none-v/--verboseSe deve registrar o progresso e os erros no console. Use esta opção se a análise estiver demorando muito e suspeitar de um problema. Padrão: sem registro -v-m/--memoryModo de baixa memória - minimiza o uso de memória do localizador de duplicatas ao custo da velocidade de análise. -m-g/--gramcomprimento do ngrama (avançado) – afeta a velocidade, o uso de memória, e a precisão da análise. A diferença depende das especificidades do conteúdo. -g=10-w/--keepWhitespaceMantém as ocorrências de múltiplos espaços consecutivos no conteúdo analisado. Por padrão, os espaços em branco são normalizados, o que significa que vários espaços consecutivos são tratados e exibidos como um só. -w-i/--inlineIncluir o conteúdo dos elementos aninhados no elemento que os envolve. Por exemplo:
<parent>Some content including <child>nested content</child></parent>Com esta opção ativada, o elemento externo será analisado como 'Some content including nested content', enquanto por padrão, ele é analisado como 'Some content including'.
-i
Exemplo de comando
Aqui está um exemplo de como seu comando pode parecer:
java -jar duplicate-finder.jar -r=/Users/me.user/my-site -i=md -f=md,mdx -s=0.85 -d=5 -l=200
O comando acima fará o seguinte:
-
-r=/Users/me.user/my-site– procurar conteúdo similar em '/Users/me.user/my-site' e seus subdiretórios -
-i=md– assumir que o conteúdo está escrito em Markdown e analisá-lo de acordo com as regras do Markdown -
-f=md,mdx– considerar apenas arquivos com as extensões '.md' e '.mdx' -
-s=0.85– reportar apenas correspondências com uma similaridade de 85% ou mais -
-d=5– reportar apenas textos que são duplicados 5 ou mais vezes -
-l=200– reportar apenas textos com 200 caracteres ou mais
Resultados
Dependendo das configurações e do tamanho do projeto, pode ser necessário esperar um pouco para que a análise seja concluída. Depois disso, os resultados serão abertos no visualizador de duplicatas e salvos na pasta definida com a opção de linha de comando '-o'. Se nenhuma opção for especificada, a saída será gravada no diretório de trabalho.
Aqui está o que você vê no visualizador de duplicatas:
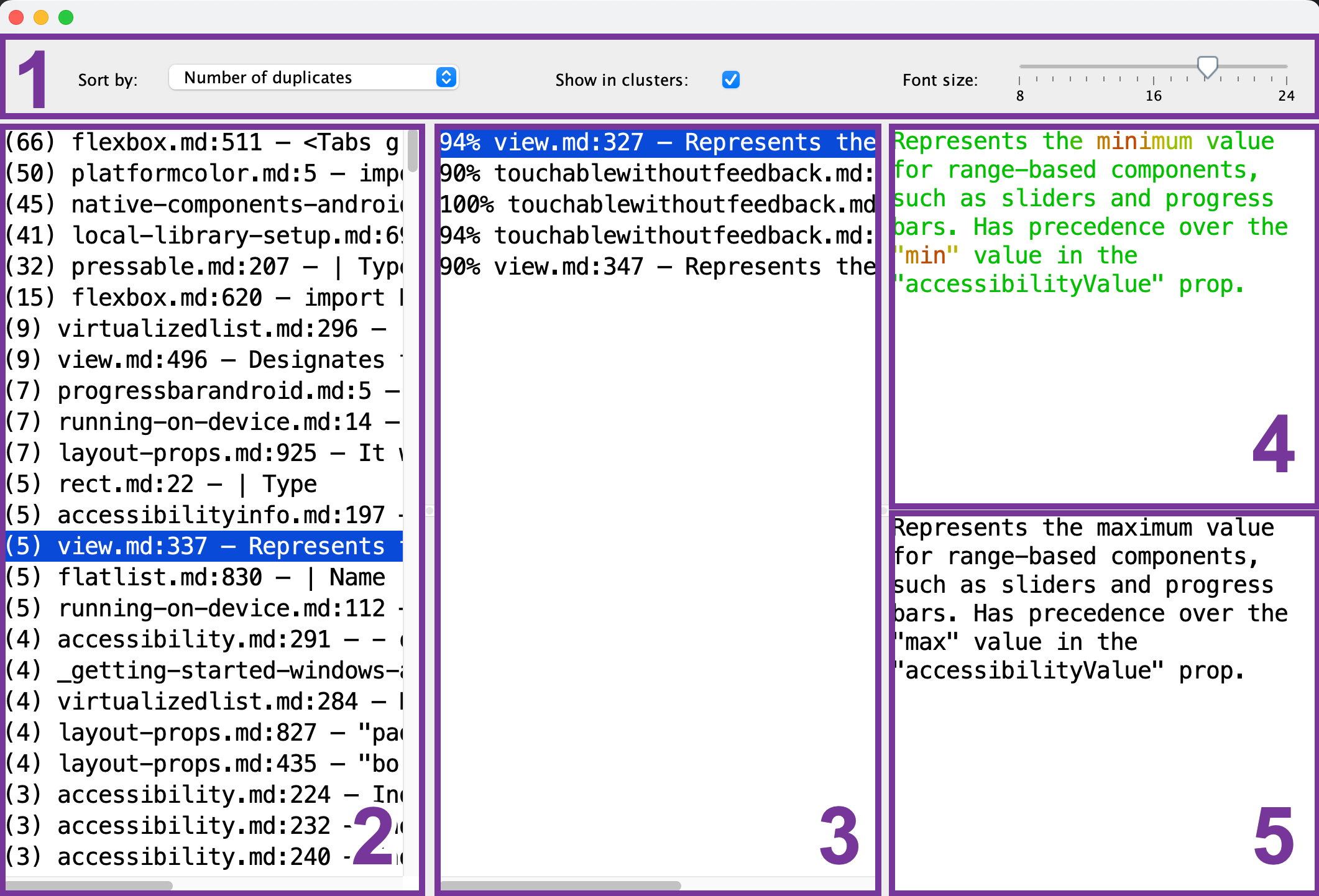
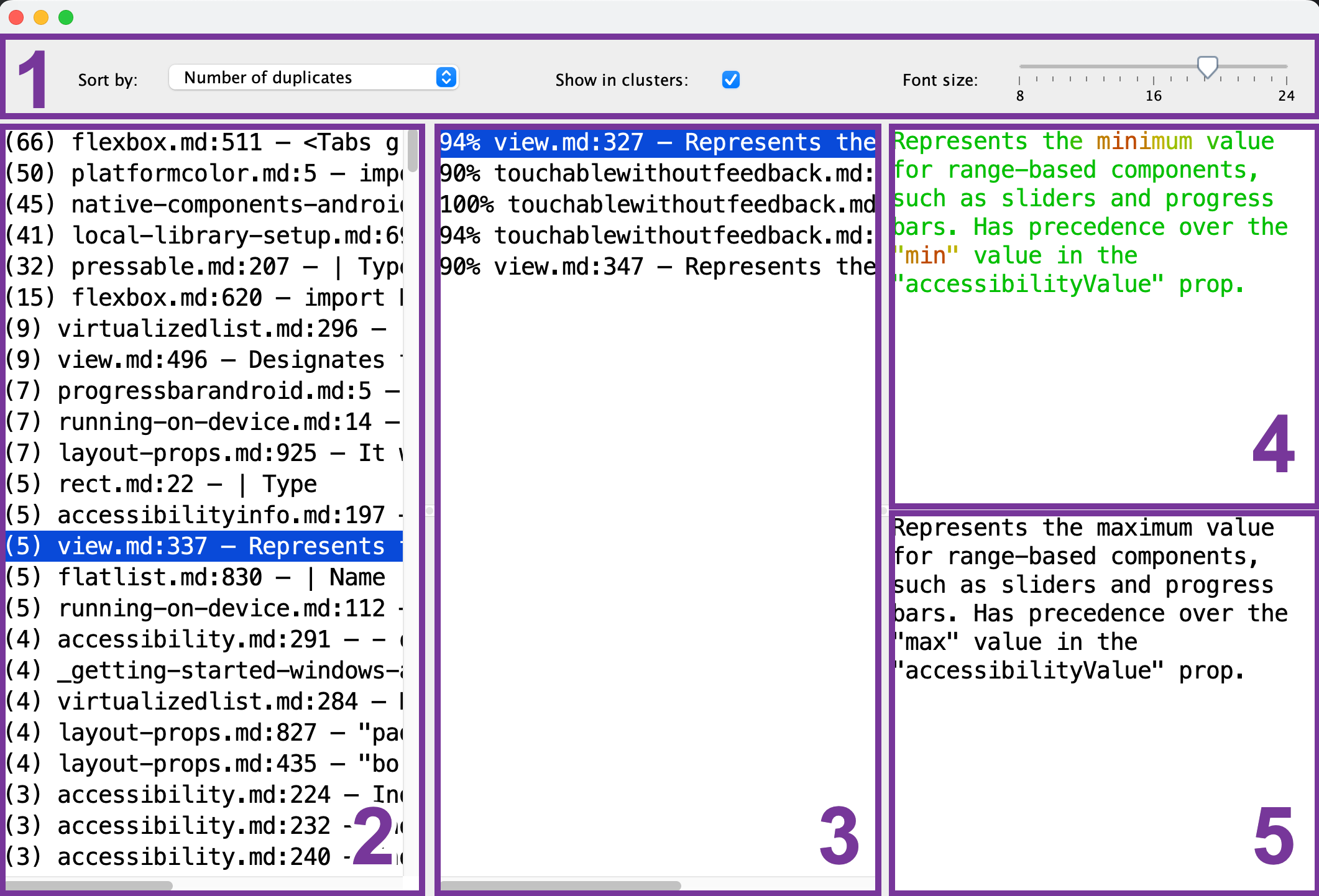
- Barra de ferramentas: configure o tamanho da fonte, a ordem de classificação e se deseja ver apenas um único fragmento de referência (2) para cada um dos grupos de duplicatas.
- Lista de fragmentos de referência: selecione o fragmento que servirá como referência para comparação.
- Lista de fragmentos duplicados: depois de selecionar o fragmento de referência (2), esta lista mostrará os fragmentos que são semelhantes a ele. Para visualizar um duplicado, selecione-o na lista.
- Pré-visualização do fragmento de referência: depois de selecionar o fragmento de referência (2), você pode visualizar seu conteúdo aqui. As partes comuns são mostradas em verde, enquanto as diferentes são mostradas em vermelho. Quanto mais fragmentos duplicados (3) tiverem essa parte em comum, mais verde aparecerá.
- Pré-visualização do fragmento duplicado: depois de selecionar o fragmento duplicado, sua pré-visualização aparecerá aqui. Você pode usá-la para uma comparação rápida com o fragmento de referência selecionado (4).
Saiba mais e entre em contato
Se você está interessado no desenvolvimento desta ferramenta, confira a série de postagens no blog relacionada:
- Localizador de Duplicatas para Texto
- Localizador de texto duplicado: Requisitos
- Junie Codes (Suporte AsciiDoc)
- Buscador de Duplicatas de Texto: Algoritmo
Para feedback, você pode entrar em contato usando os contatos no rodapé desta página. Ficarei feliz em ouvir seus pensamentos e pedidos de recursos.
Licença
O código está licenciado sob a licença MIT, o que significa que você é livre para usá-lo para qualquer propósito, assim como bifurcá-lo e modificá-lo.