KI-Skill für das Debuggen instabiler Tests
Andere Sprachen: EnglishEspañolFrançais日本語한국어Português中文
Wenn Sie schon eine Weile mit dem Internet verbunden sind, haben Sie sicherlich schon von KI-Agenten-Skills gehört. Sie bringen Ihrem Agenten dieses und jenes bei. Vielleicht haben Sie sogar selbst schon ein paar verwendet oder geschrieben.
Falls Sie noch nicht damit vertraut sind: Die Idee ist einfach. Statt für jede einzelne Aufgabe Anweisungen erneut einzugeben, definieren Sie sie einmal und verwenden sie später wieder. Eine Skill ist das KI-Äquivalent eines Wissensdatenbank-Artikels: ein einfaches Textdokument, das an einem auffindbaren Ort liegt und Schritte, eine Reihe von Konventionen oder domänenspezifisches Wissen beschreibt.
Die meisten Skills, die man so antrifft, sind für einfache Dinge gedacht, etwa um Codestil oder Commit-Message-Konventionen durchzusetzen. Aber sie können viel mächtiger sein. In diesem Artikel kombinieren wir KI-Skills, gute alte Entwickler-Tools und ein wenig kreatives Denken, um eine notorisch schwierige Aufgabe anzugehen: KI dazu zu bringen, deterministisch die Ursache instabiler Tests zu finden.
Das Problem
Zitat aus dem TeamCity CI/CD-Leitfaden:
Instabile Tests („flaky tests”) sind Tests, die sowohl bestehen als auch fehlschlagen, obwohl sich weder der Code noch der Test selbst geändert haben.
Instabilität untergräbt den ganzen Sinn von Tests: Wenn ein Test fehlschlägt, können Sie nicht sagen, ob wirklich etwas kaputt ist. Sie können sich nicht voll auf die Testergebnisse verlassen, und gleichzeitig können Sie sie nicht ignorieren. Das verschwendet sowohl menschliche als auch infrastrukturelle Ressourcen.
Und als ob die zugrunde liegenden Bugs nicht schon schwierig genug für sich wären, haben instabile Tests oft die Eigenschaft, nur bei einem von mehreren Tausend Läufen fehlzuschlagen, was sie extrem schwer reproduzierbar und debuggbar macht.
Beispielprojekt
Als Beispielprojekt nehmen wir die Webshop-Demo aus diesem Artikel: Ihre Programme sind nicht Single-Threaded. Es handelt sich um ein Spring-Boot-Projekt, in dem einer der Services ein TOCTOU-Problem (time-of-check to time-of-use) hat: Er prüft eine Bedingung und handelt dann darauf, aber ein anderer Thread kann den Zustand zwischendurch ändern. In diesem konkreten Fall kann das gelegentlich doppelte Rechnungsnummern verursachen und macht außerdem den zugehörigen Test instabil.
Hier ist der problematische Test:
@SpringBootTest
class InvoiceServiceTest {
@Autowired
private OrderService orderService;
@Test
void firstTwoOrdersGetInvoiceNumbersOneAndTwo() {
CompletableFuture<Invoice> alice = CompletableFuture.supplyAsync(
() -> orderService.checkout("Alice", BigDecimal.TEN));
CompletableFuture<Invoice> bob = CompletableFuture.supplyAsync(
() -> orderService.checkout("Bob", BigDecimal.TEN));
String num1 = alice.join().getInvoiceNumber();
String num2 = bob.join().getInvoiceNumber();
assertEquals(Set.of("INV-00001", "INV-00002"), Set.of(num1, num2));
}
}Der Test erstellt zwei Bestellungen nebenläufig und prüft, dass die resultierenden Rechnungen
die Nummern INV-00001 und INV-00002 bekommen.
Wegen eines Bugs in InvoiceService
kann er entweder zufällig bestehen oder fehlschlagen.
Wenn Sie IntelliJ IDEA verwenden, können Sie mit der Option Run until failure im Test-Runner überprüfen, ob ein Test tatsächlich instabil ist. Lassen Sie den Verdächtigen eine Weile in der Schleife laufen und schauen Sie, ob er irgendwann fehlschlägt.
Wenn wir nichts über den zugrunde liegenden Bug wüssten und nur den Test hätten – gibt es ein Werkzeug, das uns helfen könnte, die Ursache zu finden? Oder können wir uns selbst eines bauen? Und mehr noch: Können wir sowohl das Bauen als auch das Verwenden des Werkzeugs an die KI delegieren?
Die Intuition
Lassen Sie uns eine Intuition für diese Klasse von Problemen entwickeln.
Um zwei verschiedene Arten von Ergebnissen zu produzieren, muss die Ausführung
unterschiedliche Codepfade nehmen.
Der Unterschied kann minimal sein, vielleicht nur ein zusätzlicher Methodenaufruf
oder ein if -Zweig, der statt eines anderen genommen wird.
Aber er muss da sein; sonst wäre das Ergebnis konsistent.
Wenn wir also den Codepfad eines erfolgreichen und eines fehlschlagenden Laufs aufzeichnen
und dann vergleichen könnten, sollte uns der Diff zumindest in die richtige Richtung weisen.
Und idealerweise könnten wir, indem wir dem Aufrufbaum folgen, die Stelle finden, an der die Ausführung sich gabelt.
Genau diese Zeile muss der Ursprung der Instabilität sein.
Klingt diese Argumentation plausibel? Lassen Sie es uns auf die Probe stellen.
Die Werkzeuge bauen
Welches Werkzeug können wir zum Aufzeichnen von Codepfaden verwenden? Test-Coverage ist zwar nicht speziell für Tracing entwickelt, kann uns aber genau die Information liefern, die wir suchen.
Es gibt einige Java-Coverage-Tools zur Auswahl, etwa JaCoCo und das Coverage-Tool von IntelliJ IDEA. Wir entscheiden uns für das von IntelliJ IDEA, weil es die Hit-Counting-Funktion enthält. Wir brauchen diese zusätzliche Granularität möglicherweise, da die Instabilität nicht nur davon abhängen kann, was ausgeführt wird, sondern auch wie oft.
Coverage von der Kommandozeile aus ausführen
Das Coverage-Tool von IntelliJ IDEA hat eine vertraute Benutzeroberfläche, aber wir brauchen einen Weg, es programmatisch zu starten. Glücklicherweise lässt sich Coverage auch von der Kommandozeile aus erfassen, indem man den Coverage-Agenten via Maven Surefire an die JVM hängt:
mvn surefire:test \
-Dtest=com.example.webshop.service.InvoiceServiceTest \
"-DargLine=-Didea.coverage.calculate.hits=true \
-javaagent:$AGENT_JAR=$IC_FILE,true,false,false,true,com.example.webshop.*"Das Flag -Didea.coverage.calculate.hits=true
weist den Agenten an, die Anzahl der Aufrufe pro Zeile aufzuzeichnen, statt nur eine boolesche Hit/Not-Hit-Maske zu speichern.
Nach Abschluss des Tests werden die Ergebnisse in eine binäre .ic -Datei geschrieben.
So weit, so gut, aber wir brauchen den Bericht in einem für Menschen (und KI) lesbaren Format.
Textausgabe ergänzen
Zum Glück ist der IntelliJ-Coverage-Agent Open Source. Klonen wir das Projekt und bitten die KI, einen Text-Reporter hinzuzufügen, der binäre Berichte in Klartext umwandelt.
Der Agent erstellt eine neue Klasse namens TextCoverageStatistics .
Nachdem wir das Projekt gebaut und den Reporter gegen unsere .ic -Datei laufen lassen,
bekommen wir etwas wie das hier:
=== Coverage Summary ===
Instructions: 236/618 38,2%
Branches : 0/20 0,0%
Lines : 56/150 37,3%
...
=== Per-Class Coverage ===
Class Lines Line% Methods Meth%
--------------------------------------------------------------------------------------------
...
com.example.webshop.service.InvoiceNumberGenerator 4/4 100,0% 2/2 100,0%
com.example.webshop.service.InvoiceService 10/10 100,0% 3/3 100,0%
com.example.webshop.service.OrderService 6/6 100,0% 2/2 100,0%
...Der erste Teil des Berichts gibt einen Überblick auf hohem Niveau: Wie viele Zeilen, Branches und Methoden wurden im gesamten Projekt abgedeckt? Darunter folgt eine klassenweise Aufschlüsselung mit denselben Metriken für jede Klasse einzeln.
Anschließend folgen die Hit-Counts pro Zeile für jede Klasse:
--- com.example.webshop.service.InvoiceService ---
Line Hits Branch
19 2
20 1
22 2
23 2
24 2
...Für jede Zeile, die der Coverage-Agent instrumentiert hat, sehen wir, wie oft sie ausgeführt wurde und ob Branches genommen wurden. Der echte Bericht ist länger, aber Sie verstehen die Idee. Jetzt haben wir eine Textdarstellung davon, welche Zeilen ausgeführt wurden und genau wie oft.
Das ist das Rohmaterial, das wir für den Diff brauchen. So weit, so gut!
Die Berichte vergleichen
Vermutlich enthalten die so gewonnenen Berichte die nötigen Informationen, und ein sehr entschlossener Entwickler könnte sie durchforsten und den Bug finden. Aber für solche profanen Aufgaben sind wir nicht hier, oder?
Erweitern wir das Werkzeug so, dass es mehrere Bericht-Varianten erhält und den Diff präsentiert. Der kontrollierteste Weg wäre, eine Komponente nach der anderen anzugehen, aber ich denke, wir können hier das Ganze samt Automatisierung getrost an die KI delegieren:
Das resultierende Skript führt den Test in einer Schleife aus, bis beides gilt:
- wir haben mindestens einen erfolgreichen und einen fehlschlagenden Lauf.
- die angegebene Anzahl an Läufen ist abgelaufen.
Beide Bedingungen sind wichtig, denn Testfehlschläge können sehr selten sein, und die angegebene Anzahl an Läufen reicht möglicherweise nicht aus. Gleichzeitig kann es feinere Variationen innerhalb von pass- und fail-Läufen geben, die wir vielleicht ebenfalls einfangen wollen.
Sind die Berichte gesammelt, fasst das Skript die Zeilen zusammen, in denen es Variationen zwischen den Läufen gibt. Das sieht so aus:
Collected 20 runs: 12 pass, 8 fail
Lines that vary across runs:
Invoice:29 Hits(1,2)
Invoice:31 Hits(1,2)
Invoice:32 Hits(1,2)
InvoiceNumberGenerator:15 Hits(1,2)
InvoiceService:19 Hits(1,2) Branch(1/2)
InvoiceService:20 Hits(1,2)
InvoiceService:22 Hits(1,2)
InvoiceService:24 Hits(1,2)Alle Variationen folgen dem gleichen Muster: Der Unterschied ist nicht, welche Zeilen ausgeführt wurden, sondern wie oft. Wie erwartet hat sich die Hit-Counting-Funktion des Coverage-Agenten von IntelliJ IDEA als nützlich erwiesen!
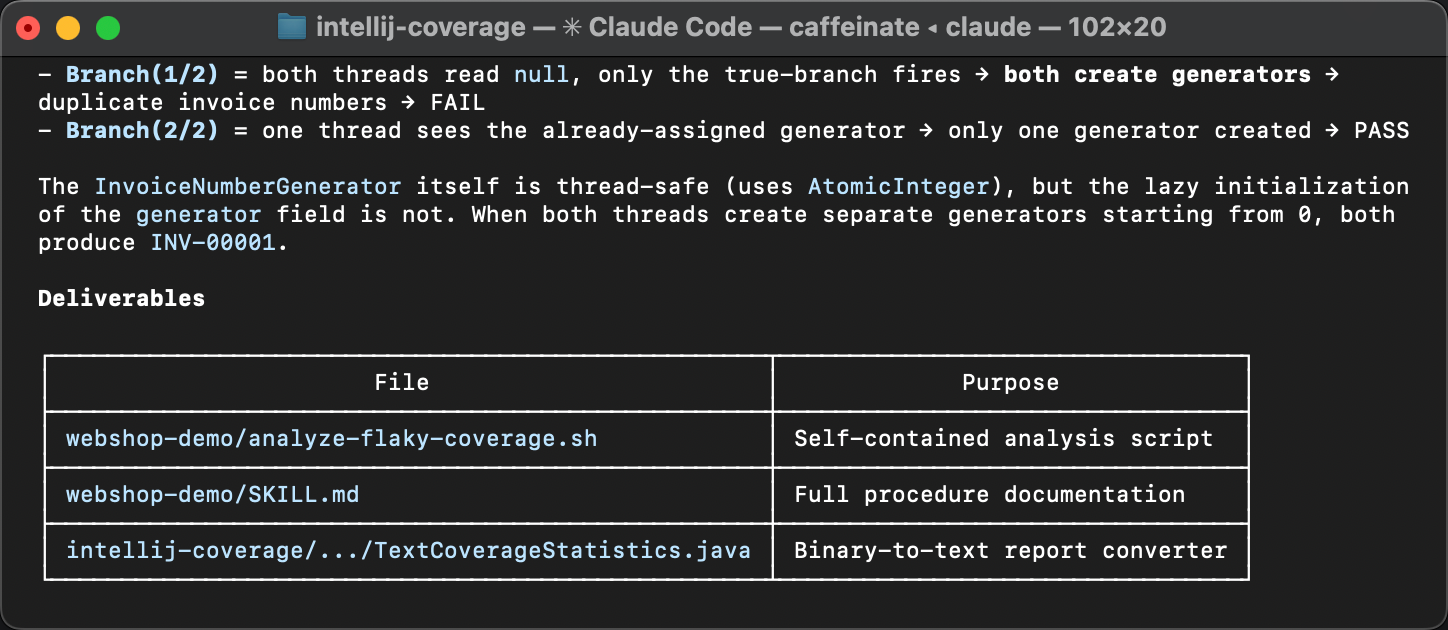
Die variierenden Zeilen verweisen auf einen Lazy-Initialisierungs-Block in InvoiceService
und seine nachgelagerten Effekte in InvoiceNumberGenerator
und Invoice .
Die Variation in den Hit-Counts bedeutet, dass die Initialisierung manchmal mehr als einmal läuft,
was nicht passieren sollte. Genau daher kommt die Instabilität.
Falls Sie den Artikel verpasst haben, der das Problem beschreibt: So entsteht der Bug durch die doppelte Initialisierung.
Die Methode createGenerator() fragt die Datenbank
nach der zuletzt verwendeten Rechnungsnummer ab und erstellt einen Zähler, der bei diesem Wert beginnt.
Wenn zwei Threads beide den Block if (generator == null) betreten,
bevor einer von ihnen ihn beendet, lesen sie dieselbe Nummer aus der Datenbank
und erstellen jeweils ihren eigenen Generator, der mit demselben Wert beginnt.
Das Ergebnis sind doppelte Rechnungsnummern.
Der Coverage-Diff hat uns genau auf jenen TOCTOU-Race-Condition hingewiesen, der im vorherigen Artikel ausführlicher besprochen wurde. Neu an unserem aktuellen Ansatz ist jedoch, dass er sich nicht allein auf menschliches Fachwissen stützt und für KI leicht zugänglich ist.
In eine Skill verwandeln
Nun würde ich sagen, dass KI-gestützte Modifikationen an Open-Source-Tools, die einem dabei helfen, die anstehende Aufgabe innerhalb von Minuten zu lösen, an sich schon erstaunlich sind. Aber behalten wir das große Ganze im Auge.
Hier ist, was wir bisher gemacht haben: Wir sind mit einer Intuition gestartet – instabile Tests nehmen unterschiedliche Codepfade, und Coverage-Analyse kann zeigen, wo sie auseinandergehen. Dann haben wir diese Intuition in eine konkrete, wiederholbare Vorgehensweise umgewandelt. Rechtfertigt das einen Wissensdatenbank-Artikel oder vielleicht eine KI-Agenten-Skill? Ja!
In derselben Agentensitzung bitten wir den Agenten:
- Sicherzustellen, dass alle Skripte in sich geschlossen und ausführbar sind.
- Die gesamte Vorgehensweise in einer
SKILL.md-Datei zu dokumentieren, Schritt für Schritt, sodass ein anderer Agent ihr ohne jeden Vorkontext folgen kann.
Der Agent packt alles zusammen und schreibt eine Anleitung, die beschreibt, wann die Skill anzuwenden ist, welche Werkzeuge benötigt werden und welche Schritte zu befolgen sind.
Die einzige Nacharbeit beim Review war, die Skill an die Spezifikation anzupassen. Die ursprüngliche Skill hatte keine Meta-Informationen im Frontmatter. Agenten sind gut darin, Skills zurechtzurücken, die kleinere Details auslassen, aber Meta-Informationen sind wichtig für die Auffindbarkeit. Ohne sie wird eine Skill von einem Agenten womöglich gar nicht erst aufgegriffen.
Die Skill testen
Um zu überprüfen, ob die Skill tatsächlich funktioniert, starten wir eine frische Agentensitzung.
Kein Aufwärmen, keine Hinweise. Stattdessen formulieren wir es bewusst sehr allgemein,
in etwa so: Find and fix the cause of flakiness in InvoiceServiceTest.
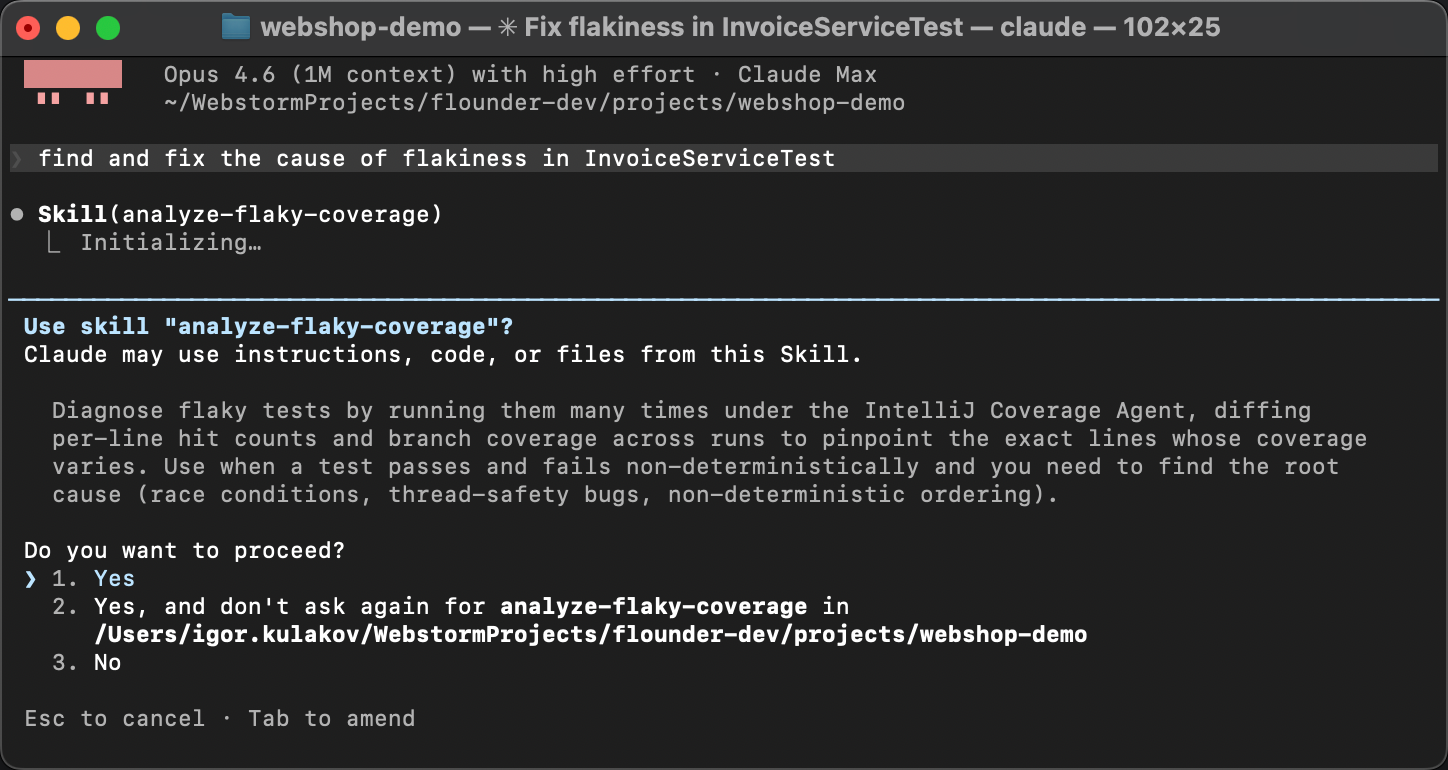
Der Agent gleicht die Skill-Beschreibung aus SKILL.md mit der Problembeschreibung ab,
findet die Anleitung und führt sie aus: Er startet das Coverage-Skript, liest den Diff
und identifiziert die Race-Condition.
Statt zu raten, folgt er den festgelegten Schritten
und kommt jedes Mal zum gleichen Ergebnis. So deterministisch, wie generative KI nur sein kann!
Zusammenfassung
Die Änderungen, die wir am Coverage-Agenten vorgenommen haben, sind bereits mit der neuen Version 1.0.774 veröffentlicht. Und die Skill ist hier verfügbar.
In diesem Artikel haben wir mit einer Intuition über instabile Tests begonnen, ein eigenes Werkzeug rund um einen Open-Source-Coverage-Agenten gebaut, es zum Auffinden einer Race-Condition verwendet und die gesamte Vorgehensweise in eine wiederverwendbare KI-Skill verpackt. Sie können diese Skill nutzen, um instabile Tests in Ihren eigenen Projekten zu finden, aber ich hoffe, dieser Beitrag vermittelt die größere Idee.
KI-Skills erlauben es Ihnen, Agenten beizubringen, praktisch alles zu lösen, solange Sie Textschnittstellen aneinanderreihen können. Viele schwierige Programmierprobleme lassen sich in einfachere zerlegen und mit vertrauten Werkzeugen lösen. Und mit der KI als Orchestrierer können wir den Prozess sogar genießen. Wie schon lange vor der KI ist Neugier die einzige echte Voraussetzung.
Viel Spaß beim Debuggen!