フレーキーテストをデバッグするためのAIスキル
他の言語: EnglishEspañolFrançaisDeutsch한국어Português中文
しばらくインターネットに接続しているなら、 AIエージェントスキルについて耳にしたことがあるはずです。 これはエージェントにあれこれの作業のやり方を教えるものです。 あなた自身もすでにいくつか使ったり書いたりしたことがあるかもしれません。
まだなじみがない方のために言うと、考え方はシンプルです。 特定のタスクのたびに手順を毎回プロンプトで指示する代わりに、一度定義しておいて後から再利用するというものです。 スキルとは、AI版のナレッジベース記事のようなもので、 発見可能な場所に置かれたプレーンテキストのドキュメントとして、 手順、規約のセット、あるいはドメイン固有の知識を記述します。
世に出回っているスキルの多くは、 コードスタイルやコミットメッセージの規約を強制するといった単純なものです。 しかし、スキルはそれよりもはるかに強力になり得ます。 この記事では、AIスキル、昔ながらの開発者ツール、そして少しの創造的思考を組み合わせて、 非常にやっかいな課題に取り組みます。 それは、AIに決定論的にフレーキーテストの根本原因を見つけさせることです。
問題
TeamCity CI/CDガイドから引用します。
フレーキーテストとは、コードやテスト自体に変更がないにもかかわらず、成功と失敗の両方を返すテストとして定義されます。
フレーキーさはテストの存在意義そのものを損ないます。テストが失敗したとき、 本当に何かが壊れているのかどうか判断できなくなるのです。 テストの結果を完全には信頼できず、同時に無視することもできません。 これは人的にもインフラ的にもリソースの無駄遣いです。
そして、根底にあるバグだけでも十分に厄介なのに、 フレーキーテストはしばしば数千回に一度しか失敗しないという性質を持ち、 再現とデバッグが極めて困難になります。
サンプルプロジェクト
サンプルプロジェクトとして、こちらの記事に登場する webショップのデモを使いましょう: あなたのプログラムはシングルスレッドではない。 これはSpring Bootプロジェクトで、サービスの1つに TOCTOU(time-of-check to time-of-use)問題があります。 条件をチェックしてからそれに基づいて動作するのですが、その間に別のスレッドが状態を変更する可能性があるのです。 この具体例では、ときどき請求書番号が重複し、対応するテストもフレーキーになります。
問題のテストはこちらです:
@SpringBootTest
class InvoiceServiceTest {
@Autowired
private OrderService orderService;
@Test
void firstTwoOrdersGetInvoiceNumbersOneAndTwo() {
CompletableFuture<Invoice> alice = CompletableFuture.supplyAsync(
() -> orderService.checkout("Alice", BigDecimal.TEN));
CompletableFuture<Invoice> bob = CompletableFuture.supplyAsync(
() -> orderService.checkout("Bob", BigDecimal.TEN));
String num1 = alice.join().getInvoiceNumber();
String num2 = bob.join().getInvoiceNumber();
assertEquals(Set.of("INV-00001", "INV-00002"), Set.of(num1, num2));
}
}このテストは2つの注文を並行して作成し、生成された請求書に
INV-00001 と INV-00002 という番号が付与されることを確認します。
InvoiceService のバグのため、
このテストはランダムに成功したり失敗したりします。
IntelliJ IDEAを使っている場合は、テストランナーの Run until failure(失敗するまで実行)オプションを使ってテストが本当にフレーキーかどうかを確認できます。 疑わしいテストをしばらく回し続けて、最終的に失敗するかどうかを観察してみましょう。
もし基盤となるバグについて何も知らず、テストだけが手元にあったとしたら、 根本原因を見つける手助けをしてくれるツールはあるでしょうか?あるいは、自分で作れるでしょうか? さらに、そのツールを構築することと使うことの両方をAIに任せることはできるでしょうか?
直感
このクラスの問題に対する直感を養いましょう。
2種類の結果を生み出すには、実行は
異なるコードパスをたどっているはずです。
その違いはごくわずかかもしれません。たとえばメソッド呼び出しが1つ余分にあるとか、
別の if 分岐をたどるといった程度かもしれません。
しかし、違いは必ずどこかにあるはずです。そうでなければ結果は一貫するはずだからです。
ですから、成功した実行と失敗した実行のコードパスを記録し、
それらを比較すれば、その差分は少なくとも正しい方向を指し示してくれるはずです。
そして理想的には、コールツリーをたどっていくことで、実行が分岐する場所を見つけられるでしょう。
その行こそが、フレーキーさが生まれるまさにその場所です。
この理屈は筋が通っているでしょうか?実際に試してみましょう。
ツールを構築する
コードパスを記録するのに、どんなツールが使えるでしょうか? トレース専用に設計されたものではありませんが、テストカバレッジから求めている情報を得ることができます。
選べるJavaのカバレッジツールはいくつかあります。たとえば JaCoCoや IntelliJ IDEAのカバレッジツールです。 今回はIntelliJ IDEAのものを使います。なぜなら、ヒット数のカウント機能を備えているからです。 フレーキーさは何が実行されたかだけでなく、何回実行されたかから生じる可能性もあるため、 この追加の粒度が必要になるかもしれません。
コマンドラインからカバレッジを実行する
IntelliJ IDEAのカバレッジツールにはおなじみのUIがありますが、 必要なのはプログラムから起動する手段です。 幸い、カバレッジはMaven Surefireを介して カバレッジエージェントをJVMにアタッチすることで、コマンドラインからも収集できます。
mvn surefire:test \
-Dtest=com.example.webshop.service.InvoiceServiceTest \
"-DargLine=-Didea.coverage.calculate.hits=true \
-javaagent:$AGENT_JAR=$IC_FILE,true,false,false,true,com.example.webshop.*" -Didea.coverage.calculate.hits=true フラグは、
単なるヒット/非ヒットのブール値マスクではなく、行ごとの呼び出し回数を記録するようエージェントに指示します。
テストが終了すると、結果はバイナリの .ic ファイルに書き込まれます。
ここまでは順調ですが、レポートを人間(およびAI)が読める形式にする必要があります。
テキスト出力を追加する
幸運なことに、IntelliJのカバレッジエージェントは オープンソースです。 プロジェクトをクローンし、AIにバイナリレポートをプレーンテキストに変換するテキストレポーターを追加してもらいましょう。
エージェントは TextCoverageStatistics という新しいクラスを作成します。
プロジェクトをビルドし、 .ic ファイルに対してそのレポーターを実行すると、
こんな出力が得られます:
=== Coverage Summary ===
Instructions: 236/618 38,2%
Branches : 0/20 0,0%
Lines : 56/150 37,3%
...
=== Per-Class Coverage ===
Class Lines Line% Methods Meth%
--------------------------------------------------------------------------------------------
...
com.example.webshop.service.InvoiceNumberGenerator 4/4 100,0% 2/2 100,0%
com.example.webshop.service.InvoiceService 10/10 100,0% 3/3 100,0%
com.example.webshop.service.OrderService 6/6 100,0% 2/2 100,0%
...レポートの最初のパートは概要を示します。 プロジェクト全体でどれだけの行、分岐、メソッドがカバーされたかが分かります。 その下には、クラスごとに同じメトリクスを示す内訳が続きます。
そしてその後に、クラスごとの行単位のヒット数が続きます:
--- com.example.webshop.service.InvoiceService ---
Line Hits Branch
19 2
20 1
22 2
23 2
24 2
...カバレッジエージェントが計装した各行について、 何回実行されたか、そしていずれかの分岐が取られたかどうかが分かります。 実際のレポートはもっと長いですが、雰囲気は伝わるでしょう。 これで、どの行が実行されたか、そして正確に何回実行されたかをテキストで表現できるようになりました。
これがdiffに必要な原材料です。ここまでは順調です!
レポートをdiffする
おそらく得られたレポートには必要な情報が含まれており、 非常に粘り強い開発者ならじっくり読んでバグを見つけられるでしょう。 でも、私たちはそんな地味な作業のためにここにいるわけではありませんよね?
ツールを拡張して、複数のレポートのバリエーションを取得し、その差分を提示するようにしましょう。 最も制御しやすいやり方は、1つずつ「ブロック」を積み上げていくことですが、 ここでは自動化も含めて、まるごとAIに任せても大丈夫だと思います:
得られたスクリプトは、以下の両方が満たされるまでテストをループで実行します:
- 少なくとも1回の成功実行と1回の失敗実行を取得する。
- 指定された実行回数に達する。
両方の条件が重要です。なぜなら、テストの失敗は非常に稀なことがあり、指定した実行回数では十分でないかもしれないからです。 同時に、成功実行と失敗実行のなかにも、より細かなバリエーションが存在し得るので、それらも捉えたいかもしれません。
レポートを収集した後、スクリプトは実行間で差異のある行を要約します。 こんな感じです:
Collected 20 runs: 12 pass, 8 fail
Lines that vary across runs:
Invoice:29 Hits(1,2)
Invoice:31 Hits(1,2)
Invoice:32 Hits(1,2)
InvoiceNumberGenerator:15 Hits(1,2)
InvoiceService:19 Hits(1,2) Branch(1/2)
InvoiceService:20 Hits(1,2)
InvoiceService:22 Hits(1,2)
InvoiceService:24 Hits(1,2)すべてのバリエーションは同じパターンを持っています。違いは、どの行が実行されたかではなく、 何回実行されたかにあります。私たちが予想したとおり、IntelliJ IDEAのカバレッジエージェントの ヒット数カウント機能が役に立ちました!
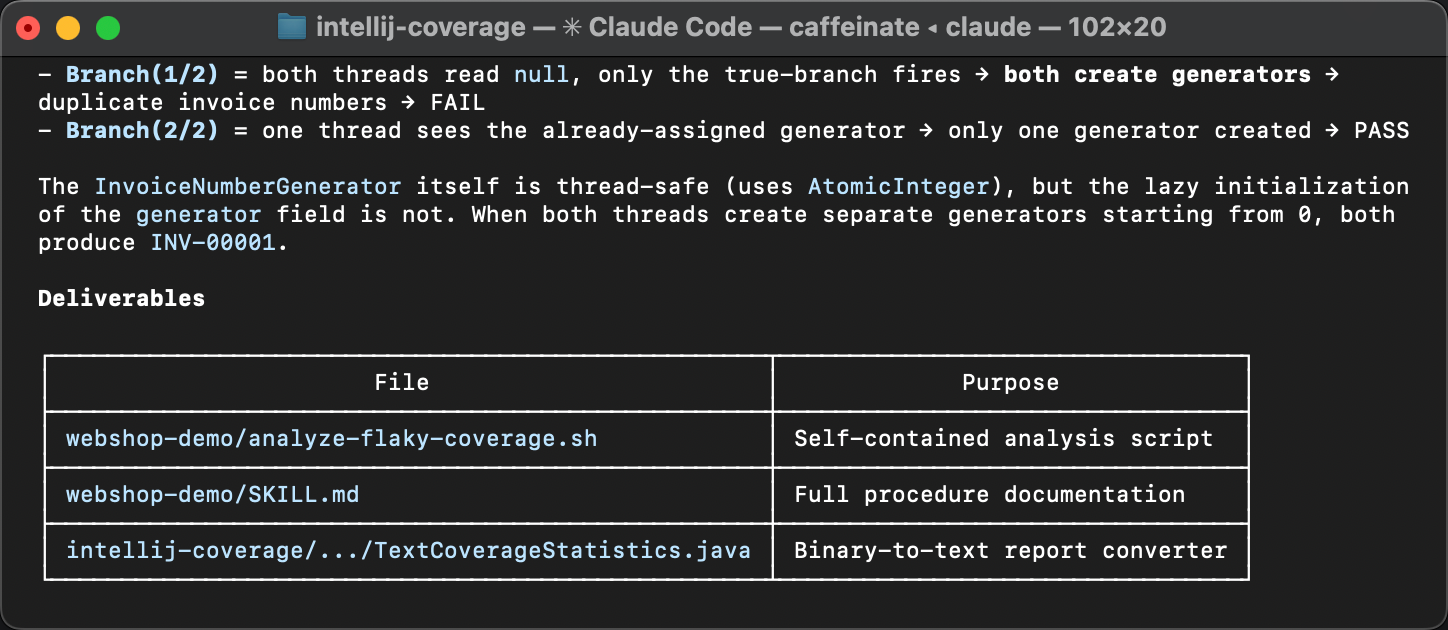
差異のある行は、 InvoiceService の遅延初期化ブロックと、
その下流の InvoiceNumberGenerator および
Invoice への影響を指し示しています。
ヒット数のばらつきは、初期化が時に複数回実行されていることを意味し、
これは本来起こるべきではありません。まさにここがフレーキーさの発生源です。
問題を解説した記事を読んでいない場合のために、二重初期化がなぜこのバグを引き起こすのかを説明します。
createGenerator() メソッドは、データベースから最後に使われた請求書番号を問い合わせ、
その値から始まるカウンタを作成します。
2つのスレッドが両方とも if (generator == null) ブロックに入り、
どちらも処理を終える前にその状態になると、それぞれが同じ番号をデータベースから読み取り、
同じ値から始まる独自のジェネレータを作成してしまいます。
結果として請求書番号が重複するわけです。
カバレッジdiffは、まさに前回の記事でより詳しく議論した TOCTOU競合を 私たちに指し示してくれました。 しかし、今回のアプローチで新しいのは、これが人間の専門知識だけに依存せず、 AIにとって容易にアクセス可能であるという点です。
スキルに仕立て上げる
AI支援によってオープンソースのツールを修正し、 目の前のタスクを数分以内に解決できる、というだけでも素晴らしいことだと思います。 しかし、もっと大きな視点を見失わないようにしましょう。
ここまで私たちがやってきたことを振り返ります。直感から始めました:フレーキーテストは異なるコードパスをたどり、 カバレッジ解析でその分岐点を明らかにできる、という直感です。 そしてその直感を、具体的で繰り返し可能な手順に落とし込みました。 これはナレッジベース記事や、もしくはAIエージェントスキルに値するでしょうか?はい、値します!
同じエージェントセッションで、エージェントに次のことを依頼しましょう:
- すべてのスクリプトが自己完結していて実行可能であることを確認する。
- 別のエージェントが何の前提知識もなくたどれるよう、手順全体を一つひとつ
SKILL.mdファイルに文書化する。
エージェントはすべてをパッケージ化し、ガイドを書きます。 そのスキルをいつ適用すべきか、どんなツールが必要か、どんな手順を踏むかが書かれています。
レビュー時のフォローアップは、スキルを仕様に合わせることだけでした。 元のスキルは、フロントマターのメタが欠けていました。 細部を取りこぼしたスキルをエージェントが整えるのは得意ですが、 メタは発見可能性のために重要です。 これがないと、そもそもエージェントがスキルを拾い上げてくれない可能性があるのです。
スキルをテストする
スキルが実際に機能することを確認するため、新しいエージェントセッションを始めましょう。
ウォームアップなし、ヒントなしです。代わりに、あえて非常に一般的な言い回しで指示します。
たとえばFind and fix the cause of flakiness in InvoiceServiceTestのような感じです。
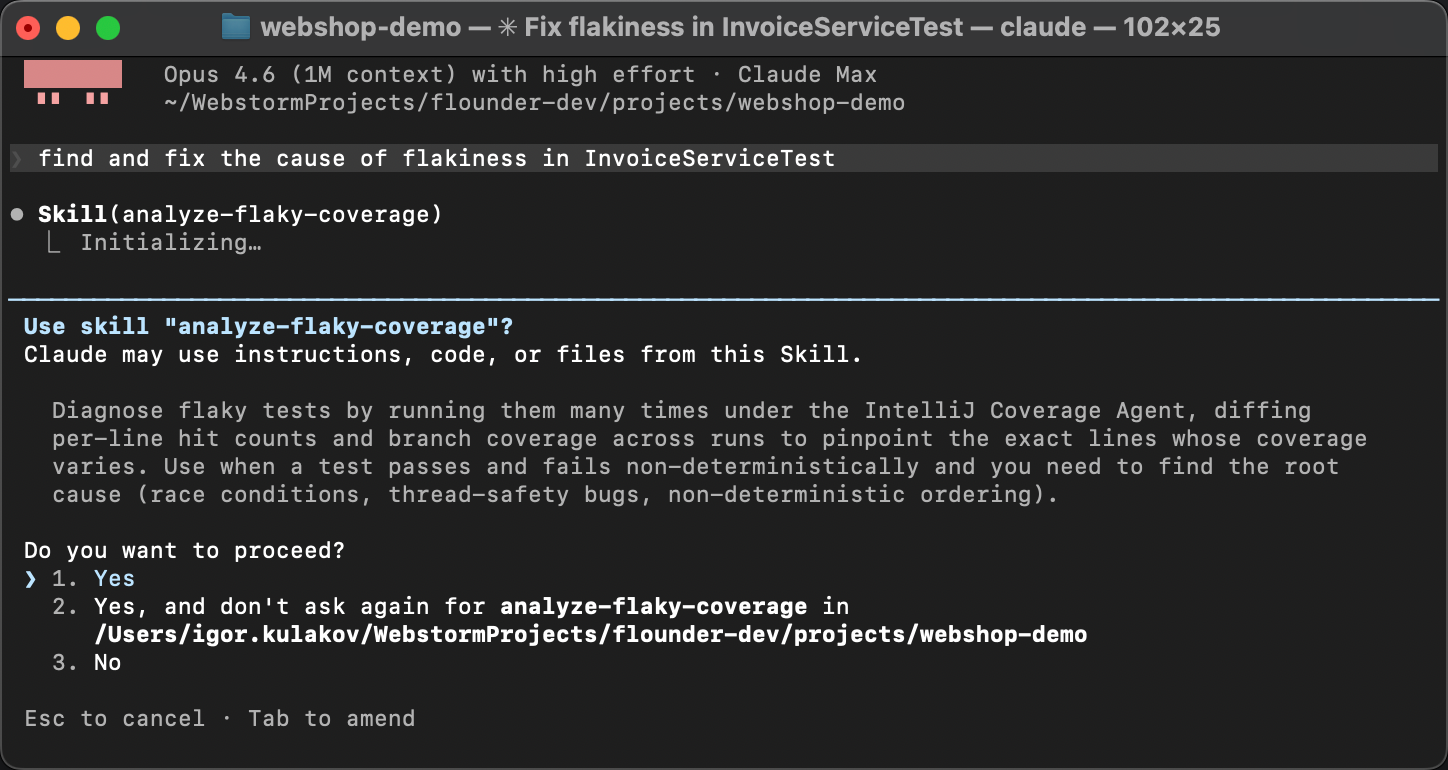
エージェントは SKILL.md のスキル説明を問題の説明と照合し、
手順を見つけ出して実行します。カバレッジスクリプトを実行し、diffを読み、
競合状態を特定します。
当てずっぽうではなく、確立された手順に従って、毎回同じ結論にたどり着きます。
生成AIでありながら、可能な限り決定論的です!
まとめ
私たちがカバレッジエージェントに加えた変更は、新しいバージョン1.0.774としてすでに公開されています。 そしてスキルはこちらから入手できます。
この記事では、フレーキーテストに関する直感から始まり、 オープンソースのカバレッジエージェントの周りにカスタムツールを構築し、 それを使って競合状態を見つけ、手順全体を再利用可能なAIスキルとしてパッケージ化しました。 このスキルを使って自分のプロジェクトのフレーキーテストを見つけることもできますが、 この投稿がもっと大きな考え方を伝えてくれていることを願っています。
AIスキルがあれば、テキストインターフェースを積み重ねられる限り、 事実上どんなことでもエージェントに教えて解決させることができます。 難しいプログラミング問題の多くは、より単純な問題に分解し、慣れ親しんだツールで解くことができます。 そしてAIがそのすべてをオーケストレートしてくれれば、 プロセスを楽しいものにすることさえできます。AIが登場するずっと前からそうであったように、 唯一の本当の前提条件は好奇心です。
ハッピー・デバッギング!