플래키 테스트 디버깅을 위한 AI 스킬
다른 언어: EnglishEspañolFrançaisDeutsch日本語Português中文
인터넷에 한동안 접속해 있었다면, AI 에이전트 스킬에 대해 분명 들어보셨을 것입니다. 스킬은 에이전트에게 이런저런 작업을 가르쳐 줍니다. 직접 사용해 보거나 작성해 본 적이 있을 수도 있습니다.
아직 익숙하지 않다면, 아이디어는 간단합니다: 특정 작업을 위한 지시 사항을 매번 프롬프트로 입력하는 대신, 한 번 정의해 두고 나중에 재사용하는 것입니다. 스킬은 지식 베이스 문서의 AI 버전이라고 할 수 있습니다: 탐색 가능한 위치에 존재하는 일반 텍스트 문서로, 단계, 일련의 컨벤션 또는 도메인별 지식을 설명합니다.
실제로 보이는 대부분의 스킬은 코드 스타일이나 커밋 메시지 컨벤션을 강제하는 것 같은 간단한 작업을 위한 것입니다. 하지만 스킬은 그보다 훨씬 강력할 수 있습니다. 이 글에서는 AI 스킬, 익숙한 개발 도구, 그리고 약간의 창의적인 사고를 결합하여 악명 높을 정도로 까다로운 작업을 다뤄보겠습니다: AI가 결정론적으로 플래키 테스트의 근본 원인을 찾아내도록 만드는 것입니다.
문제
TeamCity CI/CD 가이드를 인용하자면:
플래키 테스트(Flaky tests)는 코드 또는 테스트 자체에 변경이 없음에도 불구하고 통과와 실패를 모두 반환하는 테스트로 정의됩니다.
플래키함은 테스트의 본래 목적을 무너뜨립니다: 테스트가 실패할 때, 실제로 무언가가 망가졌는지 알 수 없습니다. 테스트 결과를 완전히 신뢰할 수도 없고, 동시에 무시할 수도 없습니다. 이는 인적 자원과 인프라 자원을 모두 낭비하게 만듭니다.
게다가 그 기저의 버그들은 그 자체로도 어려운데, 플래키 테스트는 종종 수천 번 실행 중 한 번씩만 실패하는 특성을 가지고 있어 재현하고 디버깅하는 것이 극도로 어렵습니다.
예제 프로젝트
예제 프로젝트로는 다음 글에서 다룬 웹샵 데모를 사용하겠습니다: 당신의 프로그램은 싱글 스레드가 아닙니다. 이는 Spring Boot 프로젝트로, 서비스 중 하나에 TOCTOU(time-of-check to time-of-use) 문제가 있습니다: 조건을 확인한 다음 그에 따라 동작하지만, 그 사이에 다른 스레드가 상태를 변경할 수 있습니다. 이 특정 사례에서는 때때로 중복된 송장 번호가 발생할 수 있으며, 해당 테스트도 플래키하게 만듭니다.
문제가 되는 테스트는 다음과 같습니다:
@SpringBootTest
class InvoiceServiceTest {
@Autowired
private OrderService orderService;
@Test
void firstTwoOrdersGetInvoiceNumbersOneAndTwo() {
CompletableFuture<Invoice> alice = CompletableFuture.supplyAsync(
() -> orderService.checkout("Alice", BigDecimal.TEN));
CompletableFuture<Invoice> bob = CompletableFuture.supplyAsync(
() -> orderService.checkout("Bob", BigDecimal.TEN));
String num1 = alice.join().getInvoiceNumber();
String num2 = bob.join().getInvoiceNumber();
assertEquals(Set.of("INV-00001", "INV-00002"), Set.of(num1, num2));
}
}이 테스트는 두 개의 주문을 동시에 생성하고, 결과 송장이
INV-00001 와 INV-00002 라는 번호를 받는지 확인합니다.
InvoiceService 의 버그 때문에,
이 테스트는 무작위로 통과하거나 실패할 수 있습니다.
IntelliJ IDEA를 사용 중이라면, 테스트 러너에서 Run until failure(실패할 때까지 실행) 옵션을 사용하여 테스트가 실제로 플래키한지 확인할 수 있습니다. 의심스러운 테스트를 한동안 돌려놓고 결국 실패하는지 살펴보세요.
만약 우리가 기저의 버그에 대해 아무것도 모르고 테스트만 가지고 있다면, 근본 원인을 찾는 데 도움이 될 만한 도구가 있을까요? 아니면 직접 만들 수 있을까요? 더 나아가, 이 도구를 만드는 일과 사용하는 일 모두를 AI에게 위임할 수 있을까요?
직관
이 부류의 문제에 대한 직관을 세워봅시다.
두 가지 종류의 결과를 만들어내려면, 실행이
서로 다른 코드 경로를 따라야 합니다.
그 차이는 아주 작을 수도 있습니다. 추가적인 메서드 호출 하나
또는 다른 분기 대신 선택된 if 분기 하나일 수도 있습니다.
하지만 그 차이는 반드시 존재해야 합니다. 그렇지 않으면 결과는 일관적일 것입니다.
따라서 통과한 실행과 실패한 실행의 코드 경로를 기록하고
그 둘을 비교할 수 있다면, 그 diff는 적어도 우리에게 올바른 방향을 가리켜 줄 것입니다.
그리고 이상적으로는 호출 트리를 따라가다 보면 실행이 갈라지는 지점을 찾을 수 있을 것입니다.
그 라인이 바로 플래키함이 발생하는 지점일 것입니다.
이 추론이 말이 될까요? 한 번 시험해 봅시다.
도구 만들기
코드 경로를 기록하기 위해 어떤 도구를 사용할 수 있을까요? 트레이싱을 위해 특별히 설계된 것은 아니지만, 테스트 커버리지가 우리가 원하는 정보를 제공할 수 있습니다.
선택할 수 있는 Java 커버리지 도구로는 JaCoCo와 IntelliJ IDEA의 커버리지 도구가 있습니다. 우리는 IntelliJ IDEA의 도구를 사용할 것입니다. 히트 카운팅 기능이 포함되어 있기 때문입니다. 플래키함은 무엇이 실행되었는가뿐 아니라 얼마나 많이 실행되었는가에서 비롯될 수 있기 때문에, 이 추가적인 세분성이 필요할 수 있습니다.
커맨드라인에서 커버리지 실행
IntelliJ IDEA의 커버리지 도구는 익숙한 UI를 가지고 있지만, 우리에게는 프로그램적으로 실행할 방법이 필요합니다. 다행히, Maven Surefire를 통해 JVM에 커버리지 에이전트를 연결하여 커맨드라인에서도 커버리지를 수집할 수 있습니다:
mvn surefire:test \
-Dtest=com.example.webshop.service.InvoiceServiceTest \
"-DargLine=-Didea.coverage.calculate.hits=true \
-javaagent:$AGENT_JAR=$IC_FILE,true,false,false,true,com.example.webshop.*" -Didea.coverage.calculate.hits=true 플래그는
에이전트에게 단순히 히트/논히트의 불리언 마스크가 아닌, 라인별 호출 횟수를 기록하도록 지시합니다.
테스트가 끝난 후, 결과는 바이너리 .ic 파일에 기록됩니다.
여기까지는 좋습니다. 하지만 우리는 보고서를 사람(그리고 AI)이 읽을 수 있는 형식으로 받아야 합니다.
텍스트 출력 추가
다행히도 IntelliJ 커버리지 에이전트는 오픈소스입니다. 프로젝트를 클론하고 AI에게 바이너리 보고서를 일반 텍스트로 변환하는 텍스트 리포터를 추가해달라고 요청해 봅시다.
에이전트는 TextCoverageStatistics 라는 새 클래스를 만듭니다.
프로젝트를 빌드하고 우리의 .ic 파일에 대해 리포터를 실행한 후,
다음과 같은 결과를 얻습니다:
=== Coverage Summary ===
Instructions: 236/618 38,2%
Branches : 0/20 0,0%
Lines : 56/150 37,3%
...
=== Per-Class Coverage ===
Class Lines Line% Methods Meth%
--------------------------------------------------------------------------------------------
...
com.example.webshop.service.InvoiceNumberGenerator 4/4 100,0% 2/2 100,0%
com.example.webshop.service.InvoiceService 10/10 100,0% 3/3 100,0%
com.example.webshop.service.OrderService 6/6 100,0% 2/2 100,0%
...보고서의 첫 번째 부분은 고수준의 개요를 제공합니다: 프로젝트 전체에서 몇 개의 라인, 분기, 메서드가 커버되었는지 보여줍니다. 그 아래에는 각 클래스에 대한 동일한 메트릭을 개별적으로 보여주는 클래스별 분석이 있습니다.
그다음에는 각 클래스에 대한 라인별 히트 카운트가 이어집니다:
--- com.example.webshop.service.InvoiceService ---
Line Hits Branch
19 2
20 1
22 2
23 2
24 2
...커버리지 에이전트가 인스트루먼트한 모든 라인에 대해, 몇 번 실행되었는지 그리고 어떤 분기가 선택되었는지를 볼 수 있습니다. 실제 보고서는 더 길지만, 대충 어떤 모양인지 감이 오실 겁니다. 이제 어떤 라인들이 실행되었는지, 그리고 정확히 몇 번 실행되었는지에 대한 텍스트 표현을 가지게 되었습니다.
이것이 diff에 필요한 원자재입니다. 여기까지 좋습니다!
보고서 비교
추정컨대, 얻어진 보고서에는 필요한 정보가 담겨 있고, 아주 끈기 있는 개발자라면 이를 정독하여 버그를 찾아낼 수도 있을 것입니다. 하지만 우리가 그런 평범한 작업을 하려고 여기 모인 건 아니죠?
이 도구를 업그레이드해서 여러 보고서 변형을 받아 diff를 보여주도록 만들어 봅시다. 가장 통제 가능한 방식은 한 번에 하나의 “벽돌”씩 쌓아가는 것이겠지만, 자동화를 포함하여 이 모든 것을 AI에게 맡겨도 안전할 것 같습니다:
결과 스크립트는 다음 두 가지 조건이 모두 충족될 때까지 테스트를 루프로 실행합니다:
- 적어도 한 번의 통과와 한 번의 실패 실행을 얻을 때.
- 지정된 실행 횟수를 모두 마쳤을 때.
두 조건 모두 중요합니다. 테스트 실패가 매우 드물 수 있어서, 지정된 실행 횟수가 충분하지 않을 수도 있기 때문입니다. 동시에 통과 실행과 실패 실행 내에서도 더 세밀한 변화가 있을 수 있으므로, 그것들도 잡아내고 싶을 수 있습니다.
보고서가 수집된 후, 스크립트는 실행 간에 변화가 있는 라인들을 요약합니다. 다음과 같이 보입니다:
Collected 20 runs: 12 pass, 8 fail
Lines that vary across runs:
Invoice:29 Hits(1,2)
Invoice:31 Hits(1,2)
Invoice:32 Hits(1,2)
InvoiceNumberGenerator:15 Hits(1,2)
InvoiceService:19 Hits(1,2) Branch(1/2)
InvoiceService:20 Hits(1,2)
InvoiceService:22 Hits(1,2)
InvoiceService:24 Hits(1,2)모든 변화는 동일한 패턴을 가지고 있습니다: 차이는 어떤 라인이 실행되었는가가 아니라, 몇 번 실행되었는가에 있습니다. 우리가 예상한 대로, IntelliJ IDEA 커버리지 에이전트의 히트 카운팅 기능이 유용함이 입증되었습니다!
변화하는 라인들은 InvoiceService 의 지연 초기화 블록과
InvoiceNumberGenerator 및
Invoice 에서의 그 하위 영향을 가리키고 있습니다.
히트 카운트의 변화는 초기화가 때때로 한 번 이상 실행됨을 의미하는데,
이는 일어나서는 안 되는 일입니다. 바로 그곳이 플래키함의 출처입니다.
문제를 설명한 글을 놓치셨다면, 이중 초기화가 왜 이 버그를 일으키는지 설명드리겠습니다.
createGenerator() 메서드는 마지막으로 사용된 송장 번호를
데이터베이스에 쿼리하고 그 값에서 시작하는 카운터를 만듭니다.
두 스레드가 모두 if (generator == null) 블록에 진입한 후
어느 쪽도 끝내기 전이면, 각각 데이터베이스에서 같은 번호를 읽고
같은 값에서 시작하는 자기만의 제너레이터를 만들게 됩니다.
그 결과는 중복된 송장 번호입니다.
커버리지 diff는 우리를 이전 글에서 더 자세히 다뤘던 바로 그 TOCTOU 경합으로 이끌어 주었습니다. 하지만, 우리의 현재 접근 방식에서 새로운 점은 그것이 인간의 전문성에만 의존하지 않으며 AI가 쉽게 접근할 수 있다는 것입니다.
스킬로 만들기
오픈소스 도구에 대한 AI 보조 수정만으로 당면한 작업을 모두 단 몇 분 안에 해결할 수 있다는 것은 그 자체로도 놀라운 일입니다. 하지만 더 큰 그림에 시선을 두어 봅시다.
지금까지 우리가 한 일은 다음과 같습니다: 우리는 직관에서 출발했습니다 – 플래키 테스트는 서로 다른 코드 경로를 따르며, 커버리지 분석으로 그것들이 갈라지는 지점을 드러낼 수 있다는 것이었죠. 그런 다음 우리는 그 직관을 구체적이고 반복 가능한 절차로 바꾸었습니다. 이것이 지식 베이스 글이나 AI 에이전트 스킬에 어울리는 일일까요? 그렇습니다!
같은 에이전트 세션에서, 에이전트에게 다음을 요청해 봅시다:
- 모든 스크립트가 자체 완결적이고 실행 가능한지 확인하기.
- 다른 에이전트가 사전 컨텍스트 없이 따라할 수 있도록
전체 절차를 단계별로
SKILL.md파일에 문서화하기.
에이전트는 모든 것을 패키징하고 스킬을 언제 적용해야 하는지, 어떤 도구가 필요한지, 그리고 어떤 단계를 따라야 하는지를 설명하는 가이드를 작성합니다.
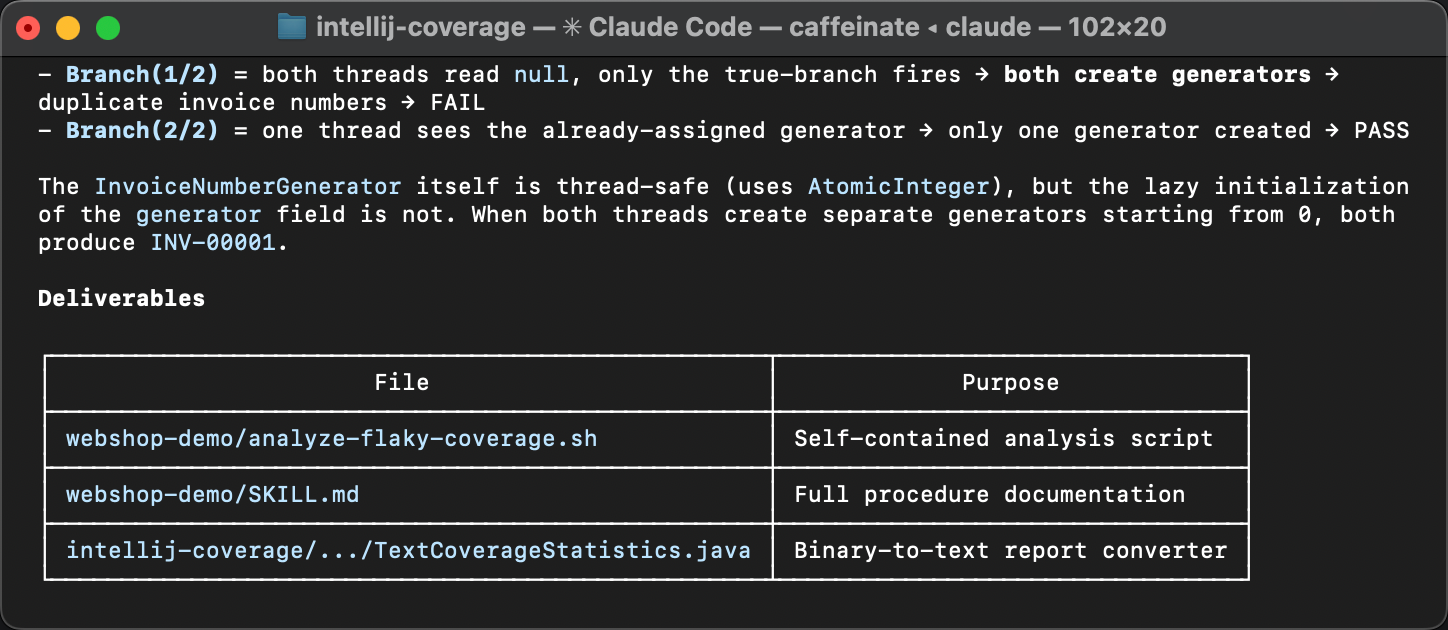
검토 중 유일한 후속 작업은 스킬을 명세에 맞추는 것이었습니다. 원본 스킬은 frontmatter에 메타가 빠져 있었습니다. 에이전트는 사소한 세부 사항이 빠진 스킬을 잘 정리해내지만, 메타는 발견 가능성을 위해 중요합니다. 메타가 없으면 스킬이 애초에 에이전트에게 선택되지 않을 수도 있습니다.
스킬 테스트하기
스킬이 실제로 작동하는지 확인하기 위해, 새로운 에이전트 세션을 시작해 봅시다.
워밍업도, 힌트도 없이. 대신, 의도적으로 매우 일반적인 방식으로 표현해 봅시다.
예를 들어 Find and fix the cause of flakiness in InvoiceServiceTest처럼요.
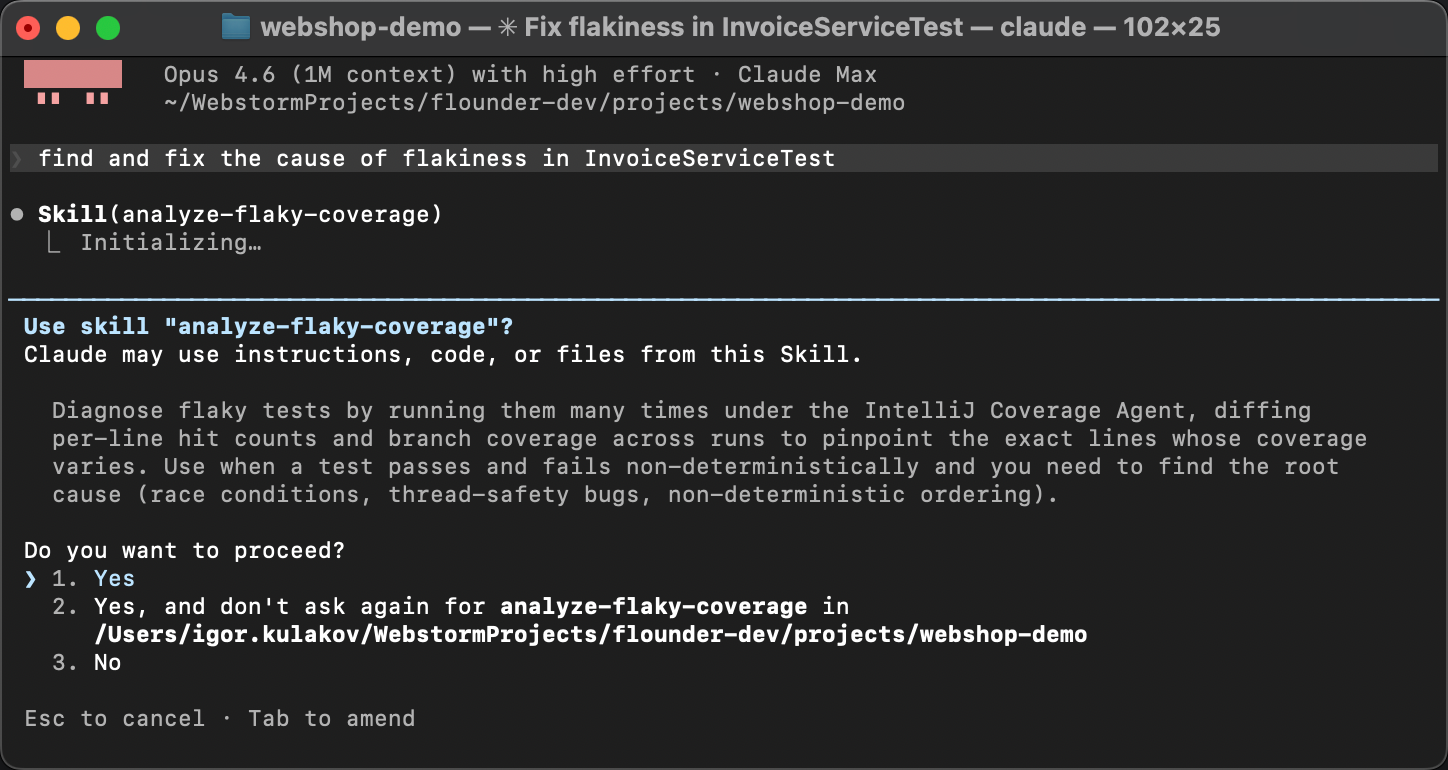
에이전트는 SKILL.md 의 스킬 설명을 문제 설명과 매칭하고,
지시 사항을 발견하여 실행합니다: 커버리지 스크립트를 실행하고, diff를 읽고,
경합 조건을 식별합니다.
추측 대신, 이미 정립된 단계를 따라
매번 같은 결론에 도달합니다. 생성형 AI가 다다를 수 있는 가장 결정론적인 모습입니다!
요약
우리가 커버리지 에이전트에 가한 변경 사항은 이미 새로운 버전 1.0.774로 발행되었습니다. 그리고 스킬은 여기에서 사용할 수 있습니다.
이 글에서 우리는 플래키 테스트에 대한 직관에서 출발하여, 오픈소스 커버리지 에이전트를 둘러싼 커스텀 툴링을 구축하고, 그것을 사용하여 경합 조건을 찾아내고, 전체 절차를 재사용 가능한 AI 스킬로 패키징했습니다. 여러분 자신의 프로젝트에서 플래키 테스트를 찾는 데 이 스킬을 사용할 수 있겠지만, 이 글이 더 큰 아이디어를 전달하기를 바랍니다.
AI 스킬은 텍스트 인터페이스를 쌓아 올릴 수만 있다면, 에이전트에게 사실상 무엇이든 해결하도록 가르칠 수 있게 해줍니다. 어려운 프로그래밍 문제 중 많은 것은 더 단순한 문제들로 분해하여 익숙한 도구를 사용해 해결할 수 있습니다. 그리고 AI가 이 모든 것을 조율한다면, 그 과정마저 즐거운 것으로 만들 수 있습니다. AI 이전 시대 오래전부터 그랬듯이, 호기심이 유일한 진정한 전제 조건입니다.
즐거운 디버깅 되세요!