Compétence IA pour déboguer les tests instables
Autres langues : EnglishEspañolDeutsch日本語한국어Português中文
Si vous êtes connecté à internet depuis un certain temps, vous avez sûrement entendu parler des compétences d’agents IA. Elles apprennent à votre agent à faire ceci ou cela. Vous en avez peut-être même utilisé ou écrit quelques-unes vous-même.
Si vous ne les connaissez pas encore, l’idée est simple : au lieu de décrire les instructions d’une tâche spécifique à chaque fois, vous les définissez une fois et les réutilisez ensuite. Une compétence est l’équivalent IA d’un article de base de connaissances : un document en texte brut, situé à un endroit où il peut être découvert, et qui décrit des étapes, un ensemble de conventions ou des connaissances spécifiques à un domaine.
La plupart des compétences que l’on rencontre dans la nature concernent des choses simples, comme l’application d’un style de code ou de conventions sur les messages de commit. Mais elles peuvent être bien plus puissantes que cela. Dans cet article, nous combinerons les compétences IA, les bons vieux outils de développement et un peu de réflexion créative pour répondre à une tâche notoirement difficile : faire en sorte que l’IA trouve, de manière déterministe, la cause racine des tests instables.
Le problème
Pour citer le guide CI/CD de TeamCity :
Les tests instables sont définis comme des tests qui renvoient à la fois des succès et des échecs malgré l’absence de modification du code ou du test lui-même.
L’instabilité sape tout l’intérêt des tests : lorsqu’un test échoue, on ne peut pas dire si quelque chose est réellement cassé. On ne peut pas se fier complètement aux résultats des tests, et en même temps, on ne peut pas les ignorer. Cela gaspille à la fois des ressources humaines et d’infrastructure.
Et comme si les bugs sous-jacents n’étaient pas déjà assez difficiles en eux-mêmes, les tests instables ont souvent cette propriété d’échouer une fois sur plusieurs milliers d’exécutions, ce qui les rend extrêmement difficiles à reproduire et à déboguer.
Projet d’exemple
Pour le projet d’exemple, prenons la démo de boutique en ligne de cet article : Vos programmes ne sont pas mono-thread. C’est un projet Spring Boot, dans lequel l’un des services présente un problème de TOCTOU (time-of-check to time-of-use) : il vérifie une condition puis agit en fonction de celle-ci, mais un autre thread peut modifier l’état entre-temps. Dans ce cas précis, cela peut parfois entraîner des numéros de facture en double et rend également le test correspondant instable.
Voici le test problématique :
@SpringBootTest
class InvoiceServiceTest {
@Autowired
private OrderService orderService;
@Test
void firstTwoOrdersGetInvoiceNumbersOneAndTwo() {
CompletableFuture<Invoice> alice = CompletableFuture.supplyAsync(
() -> orderService.checkout("Alice", BigDecimal.TEN));
CompletableFuture<Invoice> bob = CompletableFuture.supplyAsync(
() -> orderService.checkout("Bob", BigDecimal.TEN));
String num1 = alice.join().getInvoiceNumber();
String num2 = bob.join().getInvoiceNumber();
assertEquals(Set.of("INV-00001", "INV-00002"), Set.of(num1, num2));
}
}Le test crée deux commandes en parallèle et vérifie que les factures résultantes
reçoivent les numéros INV-00001 et INV-00002 .
À cause d’un bug dans InvoiceService ,
il peut soit réussir, soit échouer de manière aléatoire.
Si vous utilisez IntelliJ IDEA, vous pouvez vérifier qu’un test est réellement instable en utilisant l’option Run until failure dans l’exécuteur de tests. Laissez le suspect tourner pendant un certain temps et voyez s’il finit par échouer.
Si nous ne savions rien du bug sous-jacent, et n’avions que le test, existe-t-il un outil qui pourrait nous aider à trouver la cause racine ? Ou pouvons-nous en créer un nous-mêmes ? Mieux encore, pourrions-nous déléguer à l’IA aussi bien la création que l’utilisation de l’outil ?
L’intuition
Construisons une intuition pour cette classe de problème.
Pour produire deux types de résultats, l’exécution
doit suivre des chemins de code différents.
La différence peut être minime, peut-être seulement un appel de méthode supplémentaire
ou une branche if empruntée à la place d’une autre.
Mais elle doit exister ; sinon, le résultat serait constant.
Donc, si nous pouvions enregistrer le chemin de code d’une exécution réussie et d’une exécution échouée,
puis les comparer, le diff devrait au moins nous orienter dans la bonne direction.
Et idéalement, en suivant l’arbre d’appels, nous pourrions trouver l’endroit où l’exécution diverge.
Cette ligne doit être exactement là où l’instabilité prend sa source.
Ce raisonnement tient-il la route ? Mettons-le à l’épreuve.
Construire les outils
Quel outil pouvons-nous utiliser pour enregistrer les chemins de code ? Bien qu’elle ne soit pas conçue spécifiquement pour le traçage, la couverture de tests peut nous donner l’information recherchée.
Il existe plusieurs outils de couverture Java parmi lesquels choisir, comme JaCoCo et l’outil de couverture d’IntelliJ IDEA. Nous opterons pour celui d’IntelliJ IDEA, car il intègre la fonctionnalité de comptage des hits. Cette granularité supplémentaire pourrait nous être utile, car l’instabilité peut provenir non seulement de ce qui est exécuté, mais aussi du nombre de fois où ça l’est.
Lancer la couverture en ligne de commande
L’outil de couverture d’IntelliJ IDEA possède une interface utilisateur familière, mais nous avons besoin d’un moyen de la lancer par programmation. Heureusement, la couverture peut également être collectée depuis la ligne de commande en attachant l’agent de couverture à la JVM via Maven Surefire :
mvn surefire:test \
-Dtest=com.example.webshop.service.InvoiceServiceTest \
"-DargLine=-Didea.coverage.calculate.hits=true \
-javaagent:$AGENT_JAR=$IC_FILE,true,false,false,true,com.example.webshop.*"Le drapeau -Didea.coverage.calculate.hits=true
indique à l’agent d’enregistrer le nombre d’invocations par ligne plutôt qu’un simple masque booléen hit/non-hit.
Une fois le test terminé, les résultats sont écrits dans un fichier binaire .ic .
Jusqu’ici tout va bien, mais nous avons besoin du rapport dans un format lisible par un humain (et par une IA).
Ajouter une sortie texte
Heureusement, l’agent de couverture IntelliJ est open-source. Clonons le projet et demandons à l’IA d’ajouter un rapporteur texte qui convertit les rapports binaires en texte brut.
L’agent crée une nouvelle classe appelée TextCoverageStatistics .
Après avoir compilé le projet et exécuté le rapporteur sur notre fichier .ic ,
nous obtenons quelque chose comme ceci :
=== Coverage Summary ===
Instructions: 236/618 38,2%
Branches : 0/20 0,0%
Lines : 56/150 37,3%
...
=== Per-Class Coverage ===
Class Lines Line% Methods Meth%
--------------------------------------------------------------------------------------------
...
com.example.webshop.service.InvoiceNumberGenerator 4/4 100,0% 2/2 100,0%
com.example.webshop.service.InvoiceService 10/10 100,0% 3/3 100,0%
com.example.webshop.service.OrderService 6/6 100,0% 2/2 100,0%
...La première partie du rapport offre une vue d’ensemble : combien de lignes, de branches et de méthodes ont été couvertes pour l’ensemble du projet. En dessous, on trouve une ventilation par classe affichant les mêmes métriques pour chaque classe individuellement.
Vient ensuite le compte de hits par ligne pour chaque classe :
--- com.example.webshop.service.InvoiceService ---
Line Hits Branch
19 2
20 1
22 2
23 2
24 2
...Pour chaque ligne instrumentée par l’agent de couverture, on voit combien de fois elle a été exécutée et si des branches ont été empruntées. Le rapport réel est plus long, mais vous voyez l’idée. Nous disposons à présent d’une représentation textuelle des lignes exécutées, et exactement combien de fois.
C’est la matière première dont nous avons besoin pour le diff. Jusqu’ici, tout va bien !
Comparer les rapports
A priori, les rapports obtenus contiennent les informations nécessaires, et un développeur très déterminé pourrait les éplucher pour y trouver le bug. Mais nous ne sommes pas là pour des tâches aussi banales, n’est-ce pas ?
Améliorons l’outil pour qu’il récupère plusieurs variantes de rapport et présente le diff. La méthode la plus contrôlable serait de faire « brique » par « brique », mais je pense que nous pouvons ici déléguer l’ensemble à l’IA, automatisation comprise :
Le script résultant exécute le test en boucle jusqu’à ce que les deux conditions suivantes soient réunies :
- nous obtenons au moins une exécution réussie et une exécution échouée.
- le nombre d’exécutions spécifié est atteint.
Les deux conditions sont importantes, car les échecs de tests peuvent être très rares, et le nombre d’exécutions spécifié pourrait ne pas suffire. En même temps, il peut exister des variations plus fines au sein des exécutions réussies et échouées, et nous voulons aussi les capter.
Une fois les rapports collectés, le script résume les lignes qui présentent des variations entre les exécutions. Voici à quoi cela ressemble :
Collected 20 runs: 12 pass, 8 fail
Lines that vary across runs:
Invoice:29 Hits(1,2)
Invoice:31 Hits(1,2)
Invoice:32 Hits(1,2)
InvoiceNumberGenerator:15 Hits(1,2)
InvoiceService:19 Hits(1,2) Branch(1/2)
InvoiceService:20 Hits(1,2)
InvoiceService:22 Hits(1,2)
InvoiceService:24 Hits(1,2)Toutes les variations suivent le même schéma : la différence ne porte pas sur les lignes exécutées, mais sur le nombre de fois. Comme prévu, la fonctionnalité de comptage des hits de l’agent de couverture d’IntelliJ IDEA s’est avérée utile !
Les lignes qui varient pointent vers un bloc d’initialisation paresseuse dans InvoiceService
et vers ses effets en aval dans InvoiceNumberGenerator
et Invoice .
La variation du nombre de hits signifie que l’initialisation s’exécute parfois plus d’une fois,
ce qui ne devrait pas se produire. C’est exactement de là que provient l’instabilité.
Si vous avez raté l’article qui décrit le problème, voici pourquoi une double initialisation provoque ce bug.
La méthode createGenerator() interroge la base de données
pour récupérer le dernier numéro de facture utilisé et crée un compteur démarrant à cette valeur.
Lorsque deux threads entrent tous deux dans le bloc if (generator == null)
avant que l’un ou l’autre n’ait terminé, chacun lit le même numéro depuis la base de données
et crée son propre générateur démarrant à cette même valeur.
Le résultat : des numéros de facture en double.
Le diff de couverture nous a orientés vers cette même course critique TOCTOU détaillée plus en profondeur dans l’article précédent. Mais la nouveauté de l’approche actuelle, c’est qu’elle ne repose pas uniquement sur l’expertise humaine et qu’elle est facilement accessible à l’IA.
En faire une compétence
Maintenant, je dirais que des modifications assistées par l’IA d’outils open-source pour vous aider à résoudre la tâche en cours, le tout en quelques minutes, c’est déjà remarquable en soi. Mais gardons une vue d’ensemble.
Voici ce que nous avons fait jusqu’à présent : nous sommes partis d’une intuition : les tests instables empruntent des chemins de code différents, et l’analyse de la couverture peut révéler où ils divergent. Nous avons ensuite transformé cette intuition en une procédure concrète et reproductible. Cela mérite-t-il un article de base de connaissances, voire une compétence d’agent IA ? Oui !
Dans la même session de l’agent, demandons-lui de :
- S’assurer que tous les scripts sont autonomes et exécutables.
- Documenter toute la procédure dans un fichier
SKILL.md, étape par étape, afin qu’un autre agent puisse la suivre sans aucun contexte préalable.
L’agent emballe le tout et rédige un guide qui décrit quand appliquer la compétence, quels outils sont nécessaires et quelles étapes suivre.
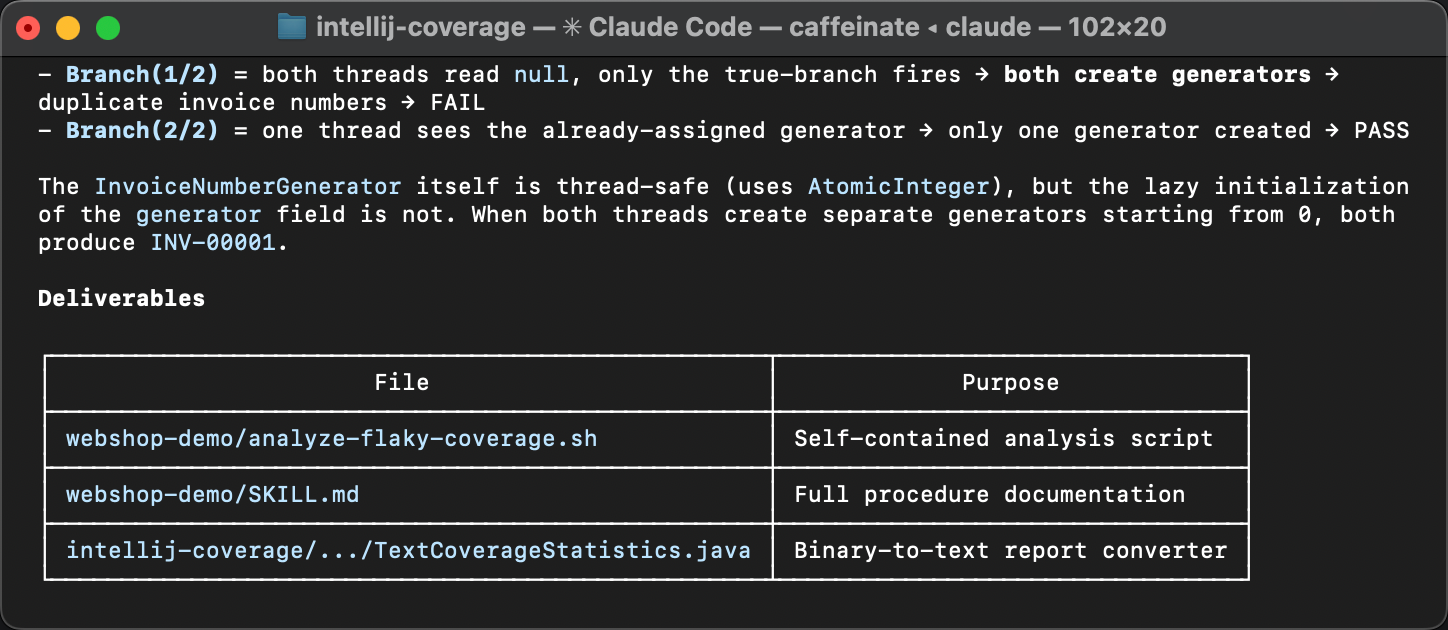
Le seul ajustement lors de la relecture a été d’aligner la compétence sur la spécification. La compétence initiale ne contenait pas de méta dans le frontmatter. Les agents savent gérer les compétences qui omettent des détails mineurs, mais le méta est important pour la découvrabilité. Sans lui, une compétence pourrait tout simplement ne pas être détectée par un agent.
Tester la compétence
Pour vérifier que la compétence fonctionne réellement, démarrons une nouvelle session d’agent.
Pas de mise en bouche, pas d’indice. Au lieu de cela, formulons la demande de manière délibérément très générale,
quelque chose comme Find and fix the cause of flakiness in InvoiceServiceTest.
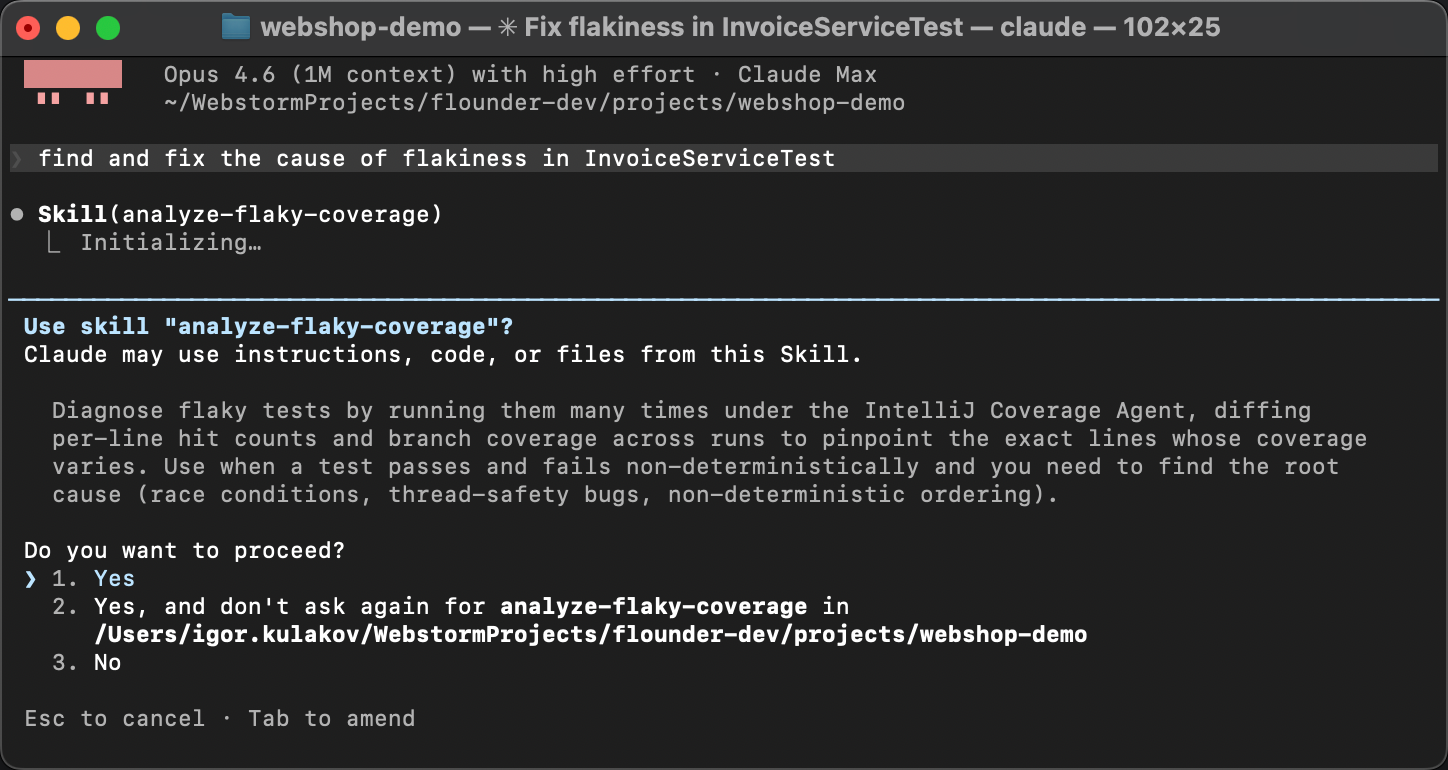
L’agent fait correspondre la description de la compétence dans SKILL.md avec la description du problème,
découvre les instructions et les exécute : il lance le script de couverture, lit le diff,
et identifie la condition de course.
Au lieu de deviner, il suit les étapes établies
et arrive à chaque fois à la même conclusion. Aussi déterministe que l’IA générative peut l’être !
Résumé
Les modifications que nous avons apportées à l’agent de couverture sont déjà publiées avec la nouvelle version 1.0.774. Et la compétence est disponible ici.
Dans cet article, nous sommes partis d’une intuition sur les tests instables, nous avons construit un outillage personnalisé autour d’un agent de couverture open-source, nous l’avons utilisé pour trouver une condition de course, et nous avons emballé l’ensemble de la procédure dans une compétence IA réutilisable. Vous pouvez utiliser cette compétence pour trouver des tests instables dans vos propres projets, mais j’espère que cet article transmet l’idée plus large.
Les compétences IA permettent d’apprendre aux agents à résoudre pratiquement n’importe quoi, tant que vous savez empiler des interfaces texte. De nombreux problèmes de programmation difficiles peuvent être décomposés en problèmes plus simples et résolus avec des outils familiers. Et avec l’IA qui orchestre tout cela, on peut même rendre le processus agréable. Comme c’était le cas bien avant l’IA, la curiosité est le seul véritable prérequis.
Bon débogage !