用于调试不稳定测试的 AI Skill
阅读其他语言: EnglishEspañolFrançaisDeutsch日本語한국어Português
如果你已经上网一段时间了, 那你一定听说过 AI agent skills。 它们能够教会你的智能体做这做那。 你甚至可能已经使用过或者自己写过几个。
如果你还不太熟悉它们,思路其实很简单: 与其每次都为某个特定任务输入指令,不如把指令定义一次,之后就可以反复使用。 一个 skill 相当于 AI 版本的知识库文章: 一份纯文本文档,存放在可被发现的位置, 描述步骤、一组约定,或某个领域特定的知识。
你在外面看到的大多数 skill 都是用来做一些简单的事情, 比如规范代码风格或提交信息约定。 但它们其实可以做的远不止这些。 在本文中,我们将把 AI skill、传统的开发者工具, 以及一点创造性思维结合起来,去解决一个出了名的难题: 让 AI 确定性地找出不稳定测试的根本原因。
问题
引用 TeamCity CI/CD 指南中的一句话:
不稳定(flaky)测试指的是在代码或测试本身没有任何变化的情况下,时而通过、时而失败的测试。
不稳定性破坏了测试存在的意义:当一个测试失败时, 你无法判断到底是不是哪里真的出了问题。 你既无法完全相信测试结果,又不能直接忽视它们。 这既浪费人力,也浪费基础设施资源。
而更糟的是,本身的 bug 已经够难排查了, 不稳定测试还经常表现为几千次运行才失败一次, 这让它们极难复现和调试。
示例项目
作为示例项目,我们采用这篇文章里的 webshop demo: 你的程序不是单线程的。 它是一个 Spring Boot 项目,其中某个服务存在 TOCTOU(检查时机与使用时机不一致)问题: 它会先检查一个条件,然后据此进行操作,但其间另一个线程可能改变了状态。 在这个例子里,它有时会导致发票号码重复,并且让相应的测试变得不稳定。
下面是这个有问题的测试:
@SpringBootTest
class InvoiceServiceTest {
@Autowired
private OrderService orderService;
@Test
void firstTwoOrdersGetInvoiceNumbersOneAndTwo() {
CompletableFuture<Invoice> alice = CompletableFuture.supplyAsync(
() -> orderService.checkout("Alice", BigDecimal.TEN));
CompletableFuture<Invoice> bob = CompletableFuture.supplyAsync(
() -> orderService.checkout("Bob", BigDecimal.TEN));
String num1 = alice.join().getInvoiceNumber();
String num2 = bob.join().getInvoiceNumber();
assertEquals(Set.of("INV-00001", "INV-00002"), Set.of(num1, num2));
}
}这个测试并发地创建两个订单,并检查生成的发票
分别拿到 INV-00001 和 INV-00002 这两个号码。
由于 InvoiceService 中有 bug,
该测试可能随机通过或失败。
如果你使用的是 IntelliJ IDEA,可以借助测试运行器中的 Run until failure(持续运行直到失败)选项来确认一个测试是否真的不稳定。 让可疑的测试持续运行一段时间,看它最终是否会失败。
如果我们对底层 bug 一无所知,手里只有这个测试,是否存在某种工具 能帮我们找到根本原因?或者我们能不能自己造一个?更进一步, 我们能不能把构建工具和使用工具这两件事都交给 AI 来做?
直觉
让我们先对这一类问题建立一些直觉。
要产生两种不同的结果,执行过程
必然走了不同的代码路径。
区别可能很小,也许只是多了一次方法调用,
或者走了 if 的另一个分支。
但它一定存在,否则结果就会是一致的。
所以,如果我们能记录下一次通过运行和一次失败运行的代码路径
然后做对比,那么差异至少可以为我们指明方向。
而理想情况下,沿着调用树往下追,我们就能找到执行发生分叉的位置。
这一行正是不稳定性的源头。
这个推理有道理吗?让我们来验证一下。
构建工具
我们可以用什么工具来记录代码路径呢? 虽然测试覆盖率并不是专为追踪而设计的,但它能提供我们想要的信息。
Java 中有几款覆盖率工具可供选择,比如 JaCoCo 和 IntelliJ IDEA 的覆盖率工具。 我们选择 IntelliJ IDEA 的工具,因为它支持命中计数功能。 我们可能需要这种额外的精度,因为不稳定性也许不仅来自哪些代码被执行, 还来自被执行了多少次。
从命令行运行覆盖率
IntelliJ IDEA 的覆盖率工具有大家熟悉的 UI, 但我们需要一种以编程方式启动它的方法。 幸运的是,覆盖率也可以通过命令行收集, 即通过 Maven Surefire 把 coverage agent 附加到 JVM:
mvn surefire:test \
-Dtest=com.example.webshop.service.InvoiceServiceTest \
"-DargLine=-Didea.coverage.calculate.hits=true \
-javaagent:$AGENT_JAR=$IC_FILE,true,false,false,true,com.example.webshop.*" -Didea.coverage.calculate.hits=true 标志
告诉 agent 记录每行的调用次数,而不仅仅是布尔值的命中/未命中标记。
测试结束后,结果会被写入一个二进制的 .ic 文件。
到目前为止还不错,但我们需要把报告变成人类(以及 AI)可读的格式。
添加文本输出
好在 IntelliJ coverage agent 是开源的。 让我们克隆该项目,并请 AI 添加一个文本报告器, 把二进制报告转换成纯文本。
智能体创建了一个名为 TextCoverageStatistics 的新类。
当我们构建项目并用这个报告器处理我们的 .ic 文件之后,
得到的结果大致是这样:
=== Coverage Summary ===
Instructions: 236/618 38,2%
Branches : 0/20 0,0%
Lines : 56/150 37,3%
...
=== Per-Class Coverage ===
Class Lines Line% Methods Meth%
--------------------------------------------------------------------------------------------
...
com.example.webshop.service.InvoiceNumberGenerator 4/4 100,0% 2/2 100,0%
com.example.webshop.service.InvoiceService 10/10 100,0% 3/3 100,0%
com.example.webshop.service.OrderService 6/6 100,0% 2/2 100,0%
...报告的第一部分给出高层概览: 整个项目中有多少行、分支和方法被覆盖。 下面是按类划分的明细,针对每个类显示同样的指标。
接下来是每个类的逐行命中计数:
--- com.example.webshop.service.InvoiceService ---
Line Hits Branch
19 2
20 1
22 2
23 2
24 2
...对于 coverage agent 注入了字节码的每一行, 我们都能看到它被执行了多少次,以及是否命中了某个分支。 真实的报告会更长,但你大概明白意思了。 现在我们有了一份关于哪些行被执行、以及精确执行次数的文本表示。
这就是做差异比较所需要的原材料。一切顺利!
对报告做差异比较
按理说,得到的报告里已经包含了必要的信息, 一个非常有耐心的开发者完全可以仔细研读它们并找到 bug。 但我们可不是来做这种繁琐工作的,对吧?
让我们升级这个工具,让它能拿到多份报告变体并展示差异。 最稳妥的方式是一砖一瓦地手工做,但我觉得这里完全可以 把整件事都交给 AI,包括自动化部分:
最终的脚本会循环运行测试,直到下面两个条件都满足为止:
- 至少有一次通过和一次失败的运行。
- 已经达到指定的运行次数。
两个条件都很重要,因为测试失败可能非常罕见,单凭指定的次数可能还不够。 同时,通过和失败的运行内部也可能存在更细粒度的差异,因此我们也想把它们捕获到。
报告收集完毕后,脚本会汇总在多次运行之间存在差异的行。 看起来是这样:
Collected 20 runs: 12 pass, 8 fail
Lines that vary across runs:
Invoice:29 Hits(1,2)
Invoice:31 Hits(1,2)
Invoice:32 Hits(1,2)
InvoiceNumberGenerator:15 Hits(1,2)
InvoiceService:19 Hits(1,2) Branch(1/2)
InvoiceService:20 Hits(1,2)
InvoiceService:22 Hits(1,2)
InvoiceService:24 Hits(1,2)所有差异都呈现同一种模式:区别不在于哪些行被执行, 而在于被执行了多少次。正如我们所预期的那样,IntelliJ IDEA 覆盖率 agent 的命中计数功能派上了用场!
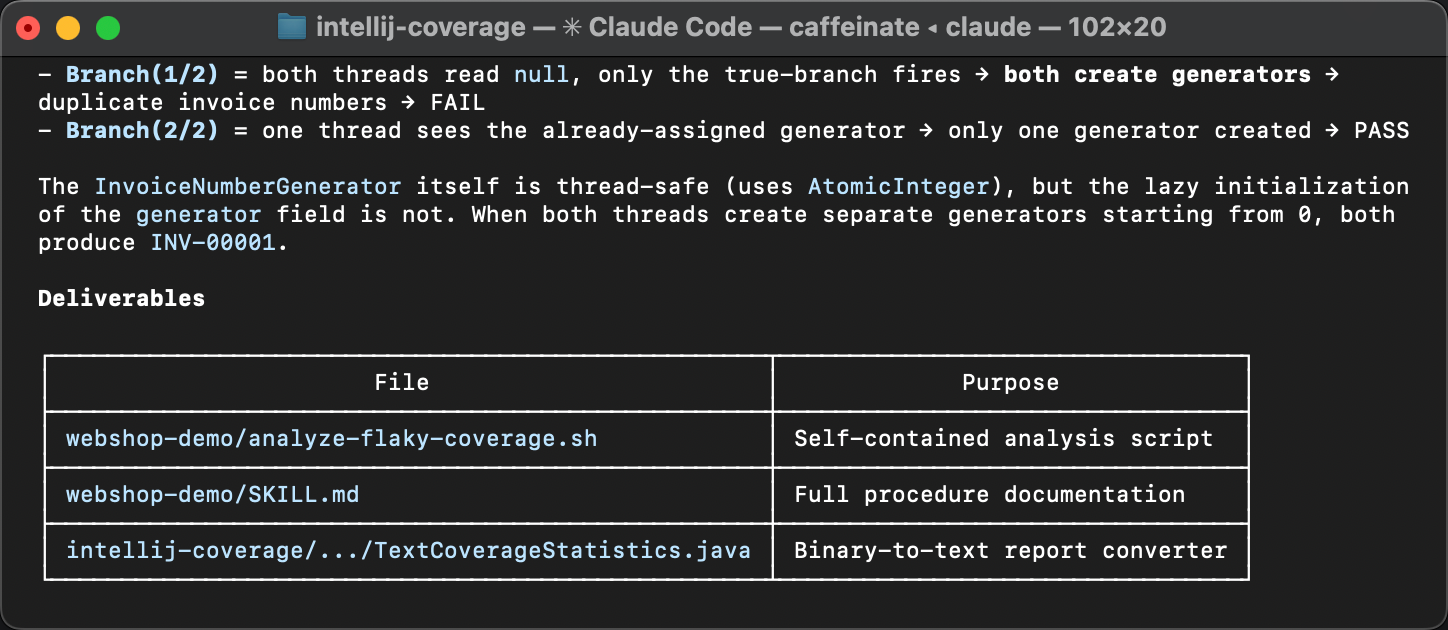
这些有差异的行指向了 InvoiceService 中的一段惰性初始化代码块,
以及它在 InvoiceNumberGenerator
和 Invoice 中的下游影响。
命中次数的差异意味着初始化有时会被执行不止一次,
而这本不该发生。这正是不稳定性的来源。
如果你没看过那篇描述这个问题的文章,下面是双重初始化为什么会引发该 bug 的原因。
createGenerator() 方法会从数据库
查询最后使用的发票号,并以该值为起点创建一个计数器。
当两个线程都在任何一方完成之前进入了
if (generator == null) 代码块,
它们各自都会从数据库读到相同的号码,
并以相同的值创建各自的生成器。
结果就是出现重复的发票号。
覆盖率差异把我们指向了 同样的 TOCTOU 竞态, 该问题在前一篇文章中有更详细的讨论。 但我们当前这种方法的新颖之处在于,它并不只依赖人类经验, 而是 AI 也很容易使用的方式。
把它变成一个 skill
说实话,能够借助 AI 在几分钟内就修改开源工具 来帮助你解决眼下的任务,这件事本身就已经很了不起了。 但让我们把目光放到更大的图景上。
到目前为止我们做了什么:从一个直觉出发——不稳定测试会走不同的代码路径, 而覆盖率分析能揭示它们在哪里产生分歧。 然后我们把这个直觉变成了一个具体的、可重复执行的流程。 这值不值得变成一篇知识库文章,或者一个 AI agent skill 呢?答案是肯定的!
在同一个智能体会话中,让我们请它:
- 确保所有脚本都是自包含且可直接运行的。
- 把整个流程在一份
SKILL.md文件中按步骤记录下来, 这样另一个智能体即使没有任何先验上下文也能照着执行。
智能体把所有内容打包,并写出一份指南, 描述何时该使用这个 skill、需要哪些工具、 以及要按什么步骤进行。
评审时唯一的后续调整是让 skill 与规范保持一致。 最初写出的 skill 在 frontmatter 中缺少 meta。 智能体在补全 skill 中遗漏的小细节方面表现不错, 但 meta 对于可发现性来说至关重要。 没有它,一个 skill 可能根本不会被某个智能体识别使用。
测试这个 skill
为了验证这个 skill 真的有效,我们启动一个全新的智能体会话。
不预热,不给提示。相反,我们刻意用一种非常笼统的方式来表达,
比如 Find and fix the cause of flakiness in InvoiceServiceTest。
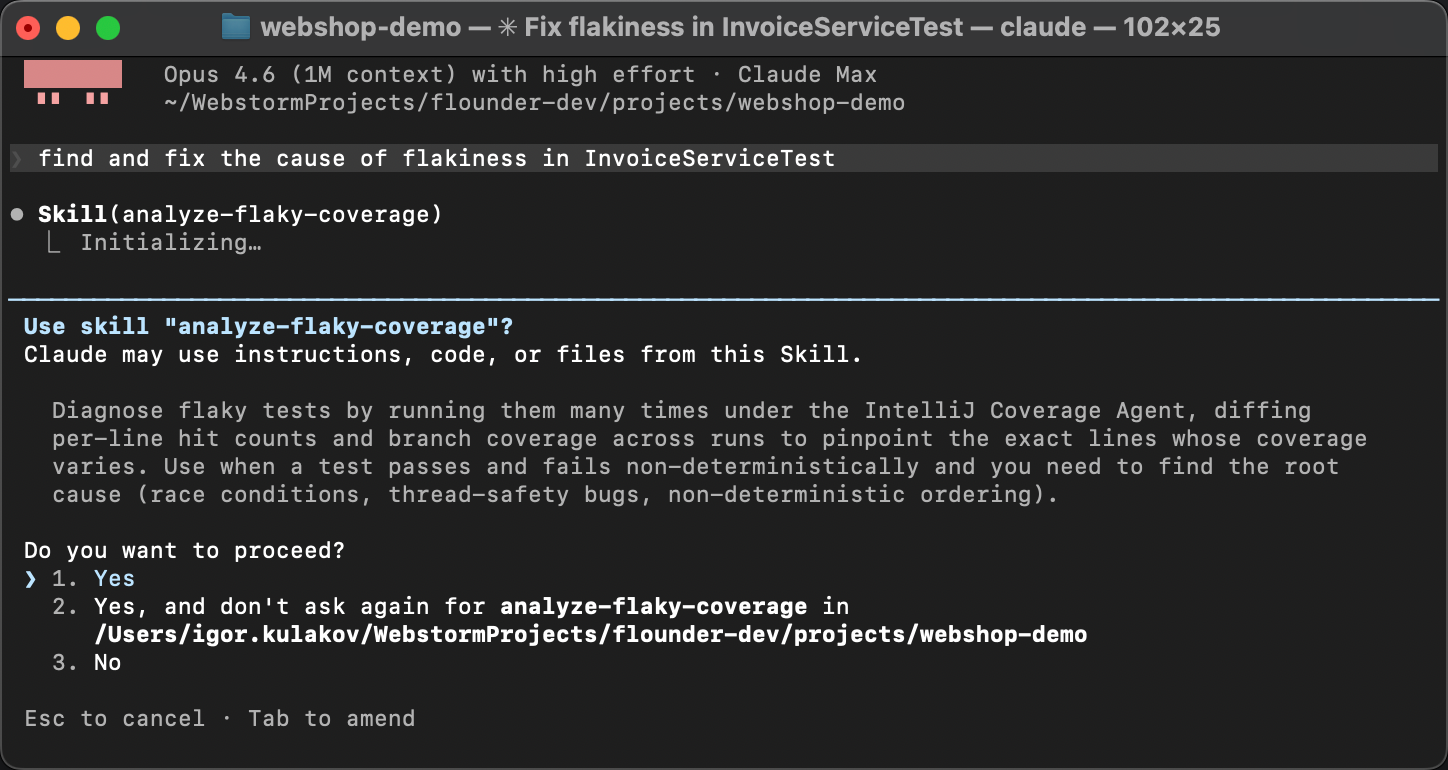
智能体把 SKILL.md 中对这个 skill 的描述与问题描述匹配上,
发现了相应的指令并执行:它运行覆盖率脚本、读取差异,
并定位到那个竞态条件。
它不是靠猜测,而是按照既定的步骤来走,
每次都得到同样的结论。这已经是生成式 AI 所能达到的最确定性的程度了!
总结
我们对 coverage agent 所做的修改已经随新版本 1.0.774 发布。 这个 skill 可以在这里获取。
在本文中,我们从对不稳定测试的一个直觉出发, 围绕一个开源 coverage agent 构建了定制化工具, 用它找出了一个竞态条件,并把整个流程打包成了一个可复用的 AI skill。 你可以用这个 skill 在自己的项目中查找不稳定测试, 但我希望这篇文章传达的是一个更大的想法。
AI skill 让你可以教智能体去解决几乎任何事情, 只要你能把一系列文本接口拼起来。许多棘手的编程问题都可以被拆解成 更简单的问题,并用熟悉的工具来解决。再加上 AI 来串联这一切, 我们甚至可以让这个过程变得有趣。和 AI 出现之前一样,好奇心仍然是唯一真正的前提。
调试愉快!