AI-навык для отладки нестабильных тестов
EnglishEspañolFrançaisDeutsch日本語한국어Português中文
Если вы давно подключены к интернету, то наверняка слышали о навыках AI-агентов. Они учат вашего агента делать то или иное. Возможно, вы даже сами использовали или писали парочку.
Если вы пока с ними не знакомы, идея проста: вместо того чтобы каждый раз заново формулировать инструкции для конкретной задачи, вы определяете их один раз и переиспользуете в дальнейшем. Навык — это AI-эквивалент статьи в базе знаний: обычный текстовый документ, который лежит в обнаружимом месте и описывает шаги, набор соглашений или предметные знания.
Большинство навыков, которые встречаются в дикой природе, посвящены простым вещам — например, соблюдению стиля кода или соглашений по сообщениям коммитов. Но они могут быть гораздо мощнее этого. В этой статье мы объединим AI-навыки, старые добрые инструменты разработчика и немного творческого мышления, чтобы решить печально известную задачу: заставить AI детерминированно находить первопричину нестабильных тестов.
Проблема
Цитата из руководства по CI/CD от TeamCity:
Нестабильными считаются тесты, которые дают как успешные, так и неуспешные результаты, несмотря на отсутствие изменений в коде или в самом тесте.
Нестабильность подрывает саму суть тестов: когда тест падает, вы не можете понять, действительно ли что-то сломано. Полностью полагаться на результаты тестов нельзя, и в то же время игнорировать их тоже нельзя. Это приводит к пустой трате как человеческих, так и инфраструктурных ресурсов.
И как будто лежащие в основе баги сами по себе недостаточно сложны, нестабильные тесты часто обладают свойством падать раз в несколько тысяч прогонов, что делает их крайне трудными для воспроизведения и отладки.
Пример проекта
В качестве примера возьмём демо интернет-магазина из этой статьи: Ваши программы не однопоточные. Это проект на Spring Boot, в котором у одного из сервисов есть проблема TOCTOU (time-of-check to time-of-use): он проверяет условие и затем действует на его основании, но другой поток может изменить состояние в промежутке. В данном конкретном случае это иногда приводит к дублирующимся номерам счетов, а также делает соответствующий тест нестабильным.
Вот проблемный тест:
@SpringBootTest
class InvoiceServiceTest {
@Autowired
private OrderService orderService;
@Test
void firstTwoOrdersGetInvoiceNumbersOneAndTwo() {
CompletableFuture<Invoice> alice = CompletableFuture.supplyAsync(
() -> orderService.checkout("Alice", BigDecimal.TEN));
CompletableFuture<Invoice> bob = CompletableFuture.supplyAsync(
() -> orderService.checkout("Bob", BigDecimal.TEN));
String num1 = alice.join().getInvoiceNumber();
String num2 = bob.join().getInvoiceNumber();
assertEquals(Set.of("INV-00001", "INV-00002"), Set.of(num1, num2));
}
}Тест создаёт два заказа параллельно и проверяет, что итоговые счета
получают номера INV-00001 и INV-00002 .
Из-за бага в InvoiceService
он может то проходить, то падать случайным образом.
Если вы используете IntelliJ IDEA, вы можете проверить, действительно ли тест нестабилен, с помощью опции Run until failure в раннере тестов. Оставьте подозреваемого крутиться какое-то время и посмотрите, упадёт ли он в итоге.
Если бы мы ничего не знали о лежащем в основе баге и у нас был только тест, есть ли инструмент, который мог бы помочь нам найти первопричину? Или мы можем сделать его сами? Более того, можем ли мы делегировать AI как создание этого инструмента, так и его использование?
Интуиция
Давайте выработаем интуицию для этого класса задач.
Чтобы давать два разных результата, выполнение
должно идти по разным путям в коде.
Разница может быть минимальной, возможно, всего один лишний вызов метода
или одна ветка if , выбранная вместо другой.
Но она должна быть, иначе результат был бы одинаковым.
Поэтому, если бы мы могли записать путь выполнения для успешного и неуспешного прогонов
и затем сравнить их, разница хотя бы указала бы нам нужное направление.
А в идеале, проследив дерево вызовов, мы могли бы найти место, где выполнение разделяется.
Эта строка должна быть именно там, откуда берётся нестабильность.
Звучит ли это рассуждение разумно? Давайте проверим его на практике.
Создаём инструменты
Какой инструмент мы можем использовать для записи путей выполнения? Хотя покрытие тестами и не предназначено специально для трассировки, оно может дать нам нужную информацию.
Есть пара инструментов покрытия для Java на выбор, например JaCoCo и инструмент покрытия в IntelliJ IDEA. Мы выберем тот, что в IntelliJ IDEA, потому что он включает в себя возможность подсчёта попаданий. Эта дополнительная детализация может нам понадобиться, потому что нестабильность может проистекать не только из того, что выполняется, но и сколько раз.
Запускаем покрытие из командной строки
Инструмент покрытия в IntelliJ IDEA имеет привычный UI, но нам нужен способ запускать его программно. К счастью, покрытие можно собирать и из командной строки, прицепив агент покрытия к JVM через Maven Surefire:
mvn surefire:test \
-Dtest=com.example.webshop.service.InvoiceServiceTest \
"-DargLine=-Didea.coverage.calculate.hits=true \
-javaagent:$AGENT_JAR=$IC_FILE,true,false,false,true,com.example.webshop.*"Флаг -Didea.coverage.calculate.hits=true
говорит агенту записывать количество вызовов на каждую строку, а не просто булеву маску попадания.
После завершения теста результаты записываются в бинарный файл .ic .
Пока всё хорошо, но нам нужен отчёт в формате, понятном человеку (и AI).
Добавляем текстовый вывод
К счастью, агент покрытия IntelliJ имеет открытый исходный код. Давайте склонируем проект и попросим AI добавить текстовый репортер, который преобразует бинарные отчёты в обычный текст.
Агент создаёт новый класс под названием TextCoverageStatistics .
После того как мы собираем проект и запускаем репортер на нашем файле .ic ,
мы получаем что-то вроде этого:
=== Coverage Summary ===
Instructions: 236/618 38,2%
Branches : 0/20 0,0%
Lines : 56/150 37,3%
...
=== Per-Class Coverage ===
Class Lines Line% Methods Meth%
--------------------------------------------------------------------------------------------
...
com.example.webshop.service.InvoiceNumberGenerator 4/4 100,0% 2/2 100,0%
com.example.webshop.service.InvoiceService 10/10 100,0% 3/3 100,0%
com.example.webshop.service.OrderService 6/6 100,0% 2/2 100,0%
...Первая часть отчёта даёт высокоуровневый обзор: сколько строк, веток и методов было покрыто во всём проекте. Ниже идёт разбивка по классам, показывающая те же метрики для каждого класса по отдельности.
Затем следуют количества попаданий по каждой строке для каждого класса:
--- com.example.webshop.service.InvoiceService ---
Line Hits Branch
19 2
20 1
22 2
23 2
24 2
...Для каждой строки, которую инструментировал агент покрытия, мы видим, сколько раз она была выполнена и были ли пройдены какие-либо ветки. Реальный отчёт длиннее, но идея понятна. Теперь у нас есть текстовое представление того, какие строки были выполнены и сколько именно раз.
Это сырой материал, который нужен нам для diff. Пока всё идёт хорошо!
Сравниваем отчёты
Предположительно, полученные отчёты содержат всю необходимую информацию, и очень упорный разработчик мог бы внимательно их изучить и найти баг. Но мы здесь не для таких приземлённых задач, верно?
Давайте улучшим инструмент так, чтобы он получал несколько вариантов отчётов и представлял их разницу. Самым контролируемым способом было бы делать по одному “кирпичику” за раз, но я думаю, что здесь мы спокойно можем делегировать всё AI, включая автоматизацию:
Получившийся скрипт запускает тест в цикле, пока не произойдёт оба следующих события:
- мы получим хотя бы один успешный и один неуспешный прогон.
- пройдёт указанное количество прогонов.
Оба условия важны, потому что падения тестов могут быть очень редкими, и указанного количества прогонов может оказаться недостаточно. В то же время внутри успешных и неуспешных прогонов могут быть и более тонкие различия, поэтому их тоже хотелось бы поймать.
После того как отчёты собраны, скрипт суммирует строки, которые отличаются между прогонами. Вот как это выглядит:
Collected 20 runs: 12 pass, 8 fail
Lines that vary across runs:
Invoice:29 Hits(1,2)
Invoice:31 Hits(1,2)
Invoice:32 Hits(1,2)
InvoiceNumberGenerator:15 Hits(1,2)
InvoiceService:19 Hits(1,2) Branch(1/2)
InvoiceService:20 Hits(1,2)
InvoiceService:22 Hits(1,2)
InvoiceService:24 Hits(1,2)У всех различий один и тот же паттерн: разница не в том, какие строки были выполнены, а в том, сколько раз. Как мы и ожидали, возможность подсчёта попаданий в агенте покрытия IntelliJ IDEA оказалась полезной!
Различающиеся строки указывают на блок ленивой инициализации в InvoiceService
и его последствия в InvoiceNumberGenerator
и Invoice .
Различия в количестве попаданий означают, что инициализация иногда выполняется более одного раза,
чего быть не должно. Именно отсюда и берётся нестабильность.
Если вы пропустили статью, описывающую проблему, вот почему двойная инициализация вызывает этот баг.
Метод createGenerator() запрашивает у базы данных
последний использованный номер счёта и создаёт счётчик, начинающийся с этого значения.
Когда два потока оба входят в блок if (generator == null)
до того, как любой из них завершится, каждый читает один и тот же номер из базы данных
и создаёт свой собственный генератор, начинающийся с того же значения.
В результате получаются дублирующиеся номера счетов.
Diff покрытия указал нам на ту самую гонку TOCTOU, которая подробнее обсуждается в предыдущей статье. Но что нового в нашем текущем подходе — он не опирается исключительно на человеческую экспертизу и легко доступен для AI.
Превращаем это в навык
Я бы сказал, что AI-сопровождаемые модификации опенсорсных инструментов, помогающие решить актуальную задачу, и всё это за считанные минуты — это уже само по себе впечатляюще. Но давайте не упускать общую картину.
Вот что мы сделали к этому моменту: мы начали с интуиции — нестабильные тесты идут по разным путям в коде, и анализ покрытия может выявить, где они расходятся. Затем мы превратили эту интуицию в конкретную, повторяемую процедуру. Заслуживает ли это статьи в базе знаний или, возможно, навыка AI-агента? Да!
В той же сессии агента давайте попросим его:
- Убедиться, что все скрипты самодостаточны и запускаемы.
- Задокументировать всю процедуру в файле
SKILL.md, шаг за шагом, чтобы другой агент мог следовать ей без какого-либо предварительного контекста.
Агент упаковывает всё и пишет руководство, описывающее, когда применять навык, какие нужны инструменты и каким шагам следовать.
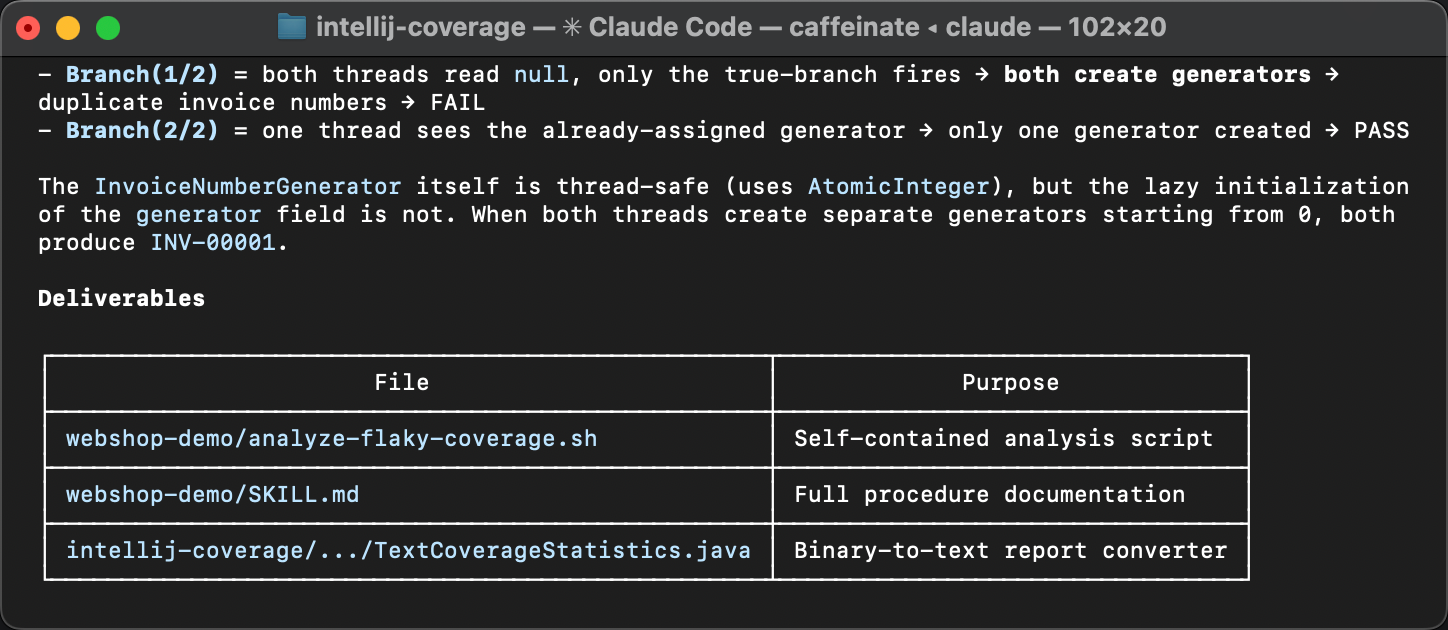
Единственная доработка на ревью — привести навык в соответствие со спецификацией. В исходном навыке во frontmatter не хватало мета-информации. Агенты хорошо разбираются с навыками, в которых упущены мелкие детали, но мета-информация важна для обнаруживаемости. Без неё навык может вообще не быть подхвачен агентом.
Тестируем навык
Чтобы убедиться, что навык действительно работает, давайте начнём свежую сессию агента.
Без разогрева, без подсказок. Вместо этого давайте намеренно сформулируем задачу очень обобщённо,
например Find and fix the cause of flakiness in InvoiceServiceTest.
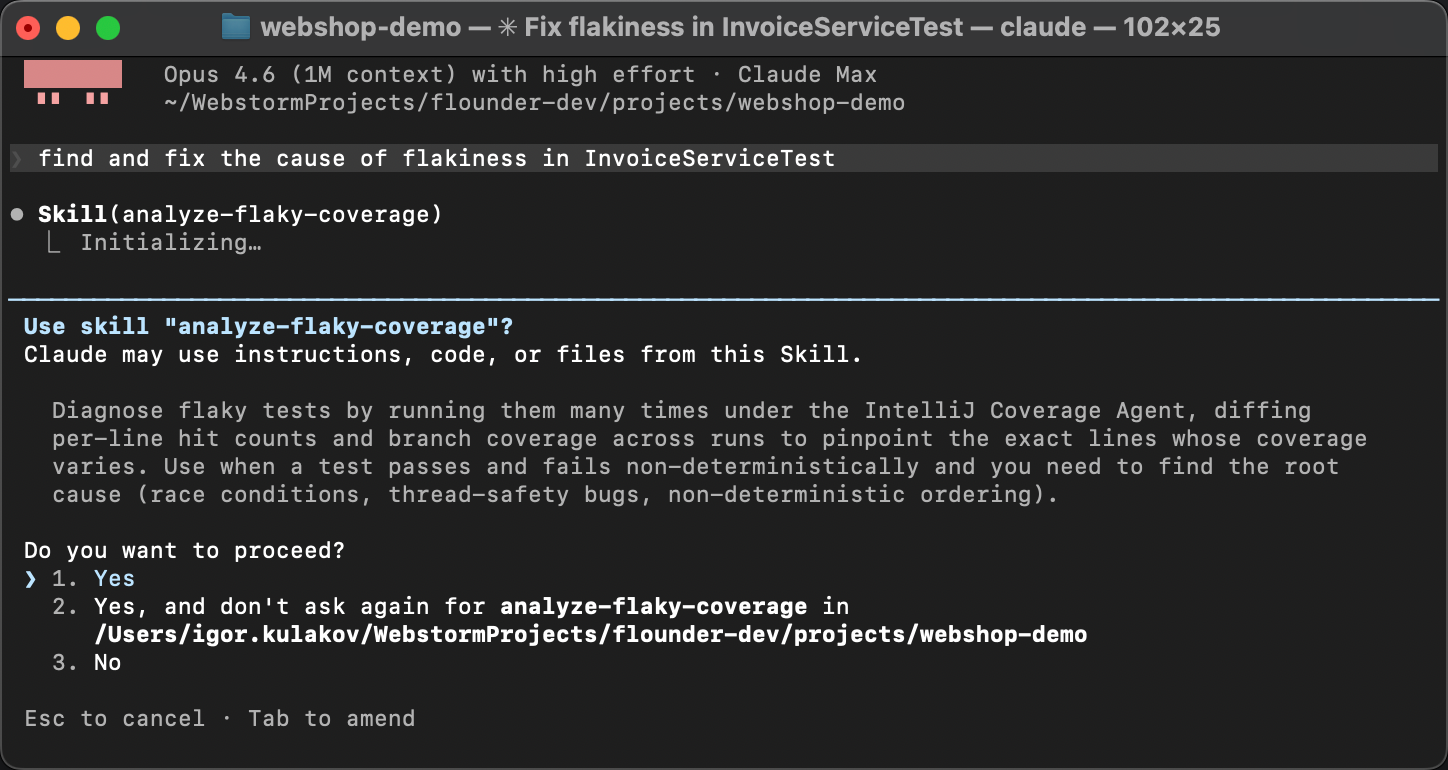
Агент сопоставляет описание навыка из SKILL.md с описанием проблемы,
обнаруживает инструкции и выполняет их: запускает скрипт покрытия, читает diff
и определяет состояние гонки.
Вместо догадок он следует установленным шагам
и каждый раз приходит к одному и тому же выводу. Настолько детерминированно, насколько может быть генеративный AI!
Итоги
Изменения, которые мы внесли в агент покрытия, уже опубликованы в новой версии 1.0.774. А сам навык доступен здесь.
В этой статье мы начали с интуиции о нестабильных тестах, построили собственную обвязку вокруг опенсорсного агента покрытия, использовали её для нахождения состояния гонки и упаковали всю процедуру в переиспользуемый AI-навык. Вы можете использовать этот навык для поиска нестабильных тестов в собственных проектах, но я надеюсь, что эта статья передаёт идею большего масштаба.
AI-навыки позволяют научить агентов решать практически что угодно, если вы можете состыковать друг с другом текстовые интерфейсы. Многие сложные проблемы программирования можно разбить на более простые и решить с помощью знакомых инструментов. А когда AI оркестрирует всё это, мы можем даже сделать процесс приятным. Как было задолго до AI, единственное настоящее условие — это любопытство.
Удачной отладки!